Most teams will tell you they’re doing continuous optimization. Their dashboards are full, their alerts are wired, and somewhere there’s a Jira ticket labeled “rightsizing.”
But when CloudBolt Chief Operating Officer Yasmin Rajabi took the stage at Converge, she shared numbers that told a different story.
“Ninety-two percent of leaders say they are mature in their optimization automation,” she cited from our Performance vs. perception: the FinOps execution gap report. “But when we looked at how often rightsizing, idle cleanup, and shutdown scheduling were a constant priority, it was only about 25 to 40 percent of the time.”
The gap between belief and behavior is the uncomfortable truth behind cloud optimization today. Most organizations aren’t falling short because they lack data or dashboards; they’re falling short because of two systemic gaps:
- A trust gap, where engineers hesitate to let automation act on their behalf.
- A timing gap, where optimization starts only after production is already in motion.
Until both close, “continuous optimization” remains more slogan than reality.
The Trust Problem
Engineers don’t distrust automation out of stubbornness. They distrust it because when something breaks, they’re the ones who get paged.
You can’t blame them either. A bad rightsizing recommendation can throttle a workload, break a release, or trigger a flood of restarts. That’s why so many teams default to manual review, even if it means the optimization backlog grows faster than the fixes.
Yasmin put it plainly: “Automation isn’t the blocker—trust is.”
Building that trust with engineers starts with guardrails, not guesses. The teams that get this right introduce automation in steps:
- Preview changes before they’re deployed.
- Set time windows (e.g. only execute at night, in dev first, etc.).
- Add thresholds such as not touching workloads unless utilization changes by 10% or more.
- Tune differently by environment (e.g. be more aggressive in non-prod, more conservative in production).
With those safeguards, engineers can start to let go without feeling like they’re losing control. Then, eventually, automation can become something they rely on rather than fear.
The Timing Problem
The second gap that gets in the way of true continuous optimization is subtler but just as damaging: optimization that starts too late.
For many teams, cost and performance tuning is still treated as a quarterly cleanup exercise or something to circle back to once everything is stable in production. Unfortunately, by then, drift and waste have already compounded.
Yasmin described it well: “If you’re waiting for production to be stable before you optimize, you’re already behind.”
True continuity means optimization starts before deployment, not after.
That’s where budget guardrails, tagging policies, and right-sizing defaults come in. When developers request new infrastructure, they should already see the projected cost and whether it fits the budget. If a large instance pushes them over, the platform should flag it or block it outright.
That shift—moving optimization earlier—changes everything. It prevents bad sizing decisions instead of remediating them. It turns “continuous optimization” from an endless backlog into an invisible safety net.
What Continuous Actually Looks Like
When trust and timing align, optimization stops being a manual process and starts becoming a property of the system itself.
Dashboards turn into signals. Signals trigger policies. And policies take action—safely, predictably, and continuously.
Yasmin shared one example of a customer that reduced its insight-to-action time from 30–90 days to literal minutes. By replacing ticket queues with policy-based automation, they cut through the lag that used to make “continuous” impossible.
Another organization, a large SaaS platform provider, used machine learning–based rightsizing to tune its Kubernetes workloads. Over time, it reduced cluster node counts from 26,000 to 5,000, cut costs by 71%, and improved uptime to 99.99%.
In both cases, the outcome wasn’t just savings—it was stability and trust. Engineers stopped firefighting and started building.
The Java Lesson
Java workloads are the perfect illustration of why trust and timing matter so much.
For years, teams have struggled with tuning Java applications in Kubernetes. Set the heap too small and you get OOM errors; set it too large and you waste memory. Traditional rightsizing tools can’t see what’s happening inside the JVM—heap usage, garbage collection, off-heap memory—so recommendations are blind guesses.
With StormForge Optimize Live, that opacity disappears. The system collects JVM-specific metrics and adjusts both the heap and the container limits together.
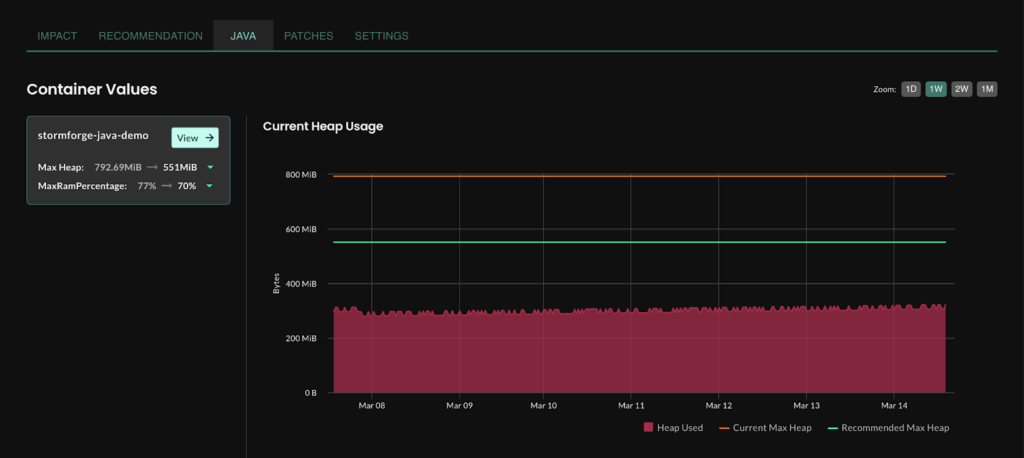
The result is JVM-aware optimization—tuning that developers can trust because it understands the workload it’s touching.
Once teams can see inside the JVM, they stop treating Java as the exception to automation and start letting optimization happen automatically.
Closing the Gaps
The Build-Manage-Optimize journey isn’t three steps—it’s one continuous loop.
- Build established how freedom and control can coexist.
- Manage confronted the myths holding teams back.
- Optimize exposes the last two barriers: trust and timing.
When those are fixed, optimization stops being an afterthought or a clean-up sprint. It just becomes part of the platform’s DNA.
Built for Kubernetes. Designed for What Comes Next.
Request a demo

Most organizations treat operational maturity like a wall of green checks. Uptime’s high. Nothing’s on fire. The dashboard’s quiet.
However, in reality, that stillness can be a sign of risk, not resilience.
In his Converge 2025 “Manage” session, CloudBolt Chief Technology & Product Officer Kyle Campos challenged the idea that maturity comes from minimizing change. “Operational maturity isn’t about avoiding change,” he said. “It’s about optimizing a continuous flow of it.”
Yet, most teams are still operating under outdated assumptions—ones that keep infrastructure static, fragile, and hard to evolve.
Here are the four myths holding teams back and what it takes to move forward.
Myth 1: High uptime is a sign of stability
“We’ve all been proud of that one server that’s been up for 427 days,” Kyle joked. “But the longer something lives untouched, the more likely it is to fail the moment you try to change it.”
Long-lived instances accumulate silent risk:
- Deployment automation atrophies
- Patches and CVEs pile up
- Configurations drift from source of truth
- Manual changes (via SSH or tribal knowledge) never get ported back
Even if your team thinks it can redeploy that infrastructure, confidence and reality often diverge. “I asked a room of ops people, ‘Could you redeploy your entire stack today?’ Half said yes. Then I asked, ‘Have you actually done it?’ Fewer hands stayed up.”
This is the atrophy effect: if you don’t exercise deployment, it decays. “Redeploy regularly, even if there’s no new code,” Kyle recommended. “Not for speed. For control.”
Myth 2: TTL is just for lab environments
Time-to-live policies are often associated with dev sandboxes and cleanup scripts. But Kyle argues they’re essential in production too because time itself should trigger change.
“There are events that trigger change—and then there’s time,” he said. “And time-based triggers are just as important for system health.”
Examples he cited include:
- Daily patch pipelines that auto-promote to image stores
- Weekly repaving of infrastructure from golden images (even without config changes)
- Scheduled credential rotation based on sensitivity level
- Periodic performance or chaos testing to validate assumptions
“Time is your enemy when infra is static,” Kyle said. “The longer it lives, the more it diverges from what you think it is.”
TTLs aren’t about deleting things for fun. They’re about operational hygiene. And when paired with codified automation, they ensure your systems can change on purpose without disruption.
Myth 3: Interdependencies block automation
Dependencies between teams, systems, and clouds are often seen as blockers. In reality, they’re just unacknowledged requirements.
“Everyone thinks, ‘I don’t have time to integrate with that other team,’” said Cofounder and VP of Customer Support & Product Architect Auggy da Rocha during the session. “But the truth is, those handoffs and constraints aren’t excuses. They’re the shape of the automation you need.”
Kyle framed it this way: “If it’s something you worry about, put it in a test. If it’s a concern, codify it. Get the anxiety out of your head and into the blueprint.”
When cross-team concerns are codified—whether it’s maintenance windows, fault domains, SLAs, or change windows—automation becomes possible because of those dependencies, not in spite of them.
Bringing It All Together
The message from Kyle’s session was clear: you can’t control what you can’t change.
- Redeploy rate is a better metric than uptime.
- Static infrastructure isn’t stable; it’s decaying.
- Time-triggered automation is maturity, not experimentation.
- And every scary interdependency is just a blueprint waiting to happen.
If operational maturity is the goal, static infra isn’t the cost of stability—it’s the barrier to it.
Standardize, codify, and orchestrate change without fear.
Schedule a custom demo
Self-service in cloud environments has always carried a certain promise: faster delivery, less friction, and fewer bottlenecks between developers and the infrastructure they need. But despite years of effort—and a long trail of portals, request forms, and automation scripts—most organizations still haven’t cracked the model.
What’s surfaced instead is a structural tension: the more flexibility teams introduce, the more risk they take on. The more they tighten control, the more they become a blocker.
Somewhere between “do everything manually” and “let everyone do whatever they want,” most platform and infrastructure teams now find themselves trying to answer a harder question: How do we enable safe, scalable self-service without losing control of cost, compliance, or complexity?
This was the central topic in the “Build” session at Converge 2025 where Chief Customer Officer Shawn Petty, Director of Global Pre-Sales Engineering Mike Bombard, and Co-Founder and VP of Customer Support & Product Architect Auggy Da Rocha drew on customer examples, operational frameworks, and hard-earned lessons from the field to reframe what successful self-service actually looks like in modern cloud environments.
Where Self-Service Breaks Down: The Limits of One-Size-Fits-All
If self-service promised to give developers faster, easier access to infrastructure, the reality has been messy. Teams either introduce too much control and become bottlenecks—or open the floodgates and lose governance entirely. Most organizations still treat this as a tradeoff.
But at scale, neither extreme holds up. “We kind of get caught in this false all-or-nothing binary around self-service,” said Shawn. “Either you lock everything down and become a bottleneck, or you open the floodgates and lose control.”
“We kind of get caught in this false all-or-nothing binary around self-service. Either you lock everything down and become a bottleneck, or you open the floodgates and lose control.”
This isn’t just a philosophical tension; it’s an operational one. In tightly controlled environments, a basic provisioning request might take weeks to fulfill. Developers, under pressure to move, start working around the system: setting up their own cloud accounts, circumventing tagging standards, and deploying infrastructure without guardrails.
In looser environments, the risk flips. Standards get ignored. Naming conventions drift. IP collisions happen. Teams end up with hundreds of unmanaged cloud artifacts and no unified way to track them. “Even minor misconfigurations—like a fat-fingered IP range—can knock a system offline,” Mike said. “And those mistakes happen more often when you’ve created a free-for-all provisioning culture.”
The real issue is that these teams are applying a single model to all workloads when what they actually need is a spectrum of models based on the workload’s requirements.
Some workloads—like regulated app backends—require rigid controls. Others—like internal dev environments—require near-total flexibility. Without a framework to differentiate between them, self-service ends up being either overly constrained or dangerously permissive.
To fix this, organizations need to move beyond the binary and start applying control and flexibility where they actually belong based on the nature of the workload, the environment, and the business risk.
That’s where blueprint-driven automation starts to matter.
Blueprint-Driven Automation: Consistency Without Bottlenecks
One of the clearest models to emerge from the Build session was the idea of blueprint-driven self-service.

Since our customer event was at the Porsche Experience Center in Atlanta, it’s only fitting that Auggy used a Porsche analogy. In Porsche’s production line, every car starts from a standard, engineered foundation: the chassis, engine, safety systems, and core electronics are all fixed. But buyers still expect to customize features like seatbelt colors, wheel options, trim packages, and interior styling. “The 911 that rolls off the line is the same across every model,” he said. “But none of us want to drive the exact same car. That’s where controlled customization comes in.”
Applied to cloud delivery, the base blueprint is the governed, reusable automation that defines the secure, compliant way to deliver a workload—a VM, a database, a Kubernetes namespace, or an entire environment. But the blueprint is designed to be extended—parameters can be exposed for dev teams to choose regions, instance sizes, or storage tiers depending on their needs.
This is how teams like Nationwide, Leidos, and others have scaled self-service without splintering into snowflake environments. But there’s nuance here. Too much flexibility inside the blueprint, and you risk losing standardization. Too little, and platform teams are forced to create dozens (or hundreds) of near-duplicate blueprints just to support common variations.
“You don’t want to shift from managing workloads to managing a blueprint for every possible flavor of that workload,” Auggy warned. “You have to leave room for flexibility without turning it into sprawl.”
This is why the strongest blueprint models rely on modular design and meaningful user inputs, not endless form fields. Devs should answer a few key questions (What kind of environment? Any compliance requirements? High availability needed?), and the blueprint logic handles the rest.
The result isn’t just speed. It’s repeatable infrastructure delivery that supports auditability, cost predictability, and developer experience all at once.
Real-World Patterns: Matching Delivery Models to Workload Realities
One of the most overlooked challenges in cloud infrastructure delivery is the assumption that every workload should be treated the same. In reality, the requirements for delivering a PCI-regulated application backend are radically different from those of a research prototype or a proof-of-concept dev environment.
During the Build session, Mike and Auggy laid out a framework many mature platform teams are now using: Map your workloads along a spectrum of control and flexibility, then build delivery models around those patterns.
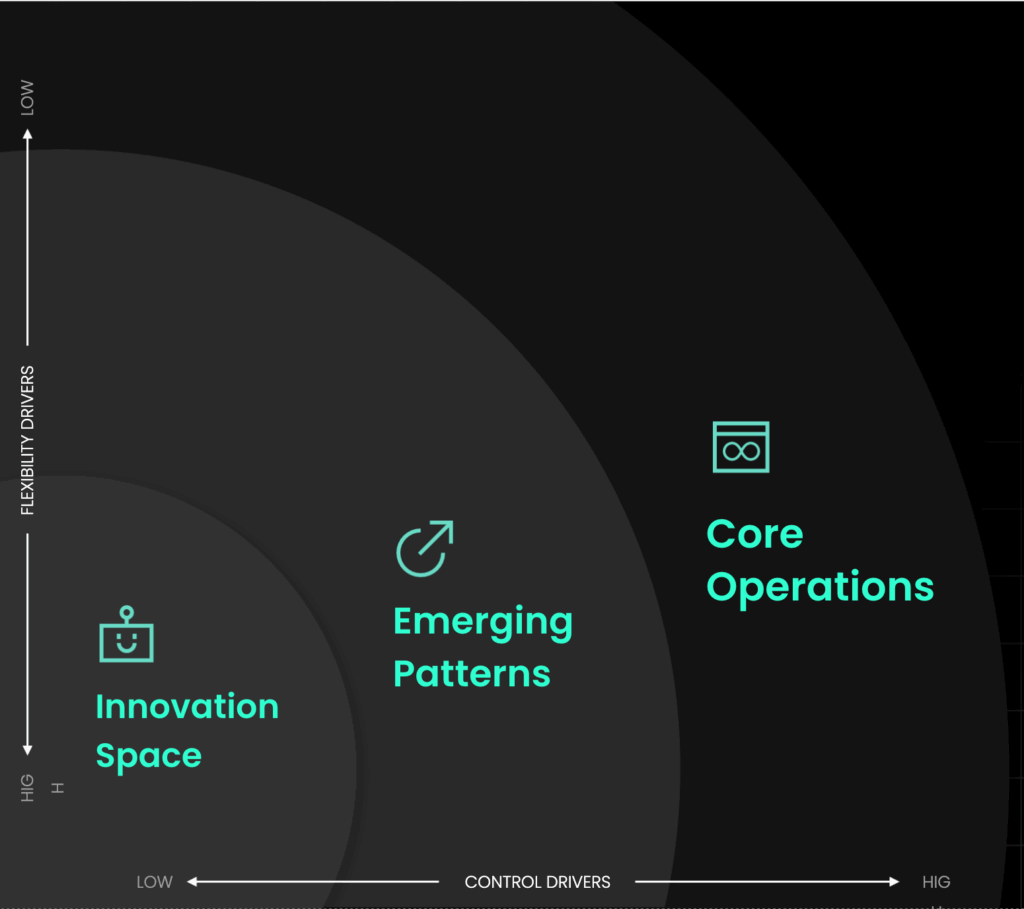
At one end of the spectrum are what Mike called core operations—workloads that have to be provisioned the same way every time. These include environments governed by compliance frameworks like PCI, HIPAA, or FedRAMP, where even minor deviations can trigger audit failures or security vulnerabilities. In these cases, control is non-negotiable: predefined templates, pre-approved configurations, and strict deployment standards are required. “You have no margin for error when it comes to compliance,” he said. “The platform should make sure those environments are provisioned correctly every single time—no exceptions.”
In the middle of the spectrum, you have repeatable workloads with slight variations—like point-of-sale (POS) deployments across retail stores. For some locations, the baseline environment is sufficient. For others—high-traffic stores or locations with specialized hardware—additional resources or custom configurations may be needed. These situations benefit from blueprint-driven automation with optional parameters that allow scaling or minor adjustments without altering the core architecture.
At the far end of the spectrum are innovation or R&D use cases—highly dynamic, often experimental environments where speed and flexibility matter more than standardization. Trying to enforce strict provisioning patterns here doesn’t just frustrate developers, it actively slows the business down. “I was just talking to a customer last week,” Auggy said. “Their developers are as cloud-native as it gets, and they’re allowed to go to AWS directly. But when they go through the internal platform, security and compliance is handled for them. It’s not a mandate—it’s a better experience.”
This spectrum-based approach acknowledges that not all infrastructure needs the same guardrails, and that the most effective platform teams apply controls where they matter and get out of the way where they don’t.
What Good Looks Like
In organizations that have closed the self-service gap, a few patterns consistently show up—not just in tooling, but in mindset and process:
1. Self-service is designed around patterns, not exceptions.
Instead of reacting to every one-off request with a new ticket or custom script, platform teams define reusable patterns for common workloads. They then continuously refine those patterns over time.
2. Governance is built in, not bolted on.
Security policies, tagging standards, budget controls, and approvals are embedded into the provisioning logic. That way developers don’t have to think about them, and ops teams don’t have to chase them down.
3. Flexibility is intentional.
Teams expose only the variables that matter, and only where it’s safe to do so. The result is self-service that feels permissive to the user but is actually tightly controlled behind the scenes.
4. Devs use the platform because it’s better, not because it’s required.
When you provide an internal experience that makes life easier, reduces risk, and delivers faster results, developers will choose it. Not out of obligation, but because it works.
Final Thought
Cloud complexity isn’t going away. If anything, it’s increasing—spanning more teams, more environments, more constraints. But the answer isn’t to pull everything behind a gate and call it governance. Neither is it letting go of the wheel and hoping for the best.
The answer is a platform model that respects the needs of the business and the realities of engineering by combining blueprint-driven automation, intelligent governance, and workload-aware flexibility into a model that actually works at scale.
Build Once, Govern Everywhere
Book a demo
Part 3 of our series unpacking the 2025 CloudBolt Industry Insights (CII) Report
Cloud has always promised value: faster time to market, greater agility, operational efficiency, and lower cost of ownership.
But for all the dashboards, alerts, and tooling investments over the years, most FinOps teams still can’t answer a basic question with confidence:
Are we actually getting a return on our cloud spend?
According to the 2025 CloudBolt Industry Insights (CII) Report, 78% of IT leaders say they still struggle to demonstrate cloud ROI—not just to finance, but to the business at large.
This third post in the Inside the Execution Gap series looks at why that gap persists, what’s blocking visibility into real value, and what it will take to shift from reporting to results.
The value we expect—but struggle to prove
When we asked IT leaders what outcomes they expect from cloud investments, the answers were clear:
- Faster time to market
- Revenue growth and innovation
- Improved cost-efficiency
- Stronger security and compliance
But the ability to link spend to those outcomes remains elusive. Three common issues surfaced in the research:
- Unclear connections between cloud costs and business results
- Misalignment between teams on priorities and metrics
- Inconsistent execution on tagging, forecasting, and allocation
And as CloudBolt CTPO Kyle Campos noted during our recent webinar, Beyond the Dashboard: Why FinOps Must Evolve for AI, Automation, and Reality, the challenge isn’t data—it’s context and follow-through.
“A lot of FinOps teams feel like they’re being pulled in ten different directions,” Kyle said. “If there’s an anomalous spike, it derails weeks of progress. And when business leaders ask for ROI, it’s hard to show value if you’re stuck firefighting.”
That firefighting often looks like productivity, but it masks a deeper problem.
Tracy Woo, Principal Analyst at Forrester, added tjos: “Have you been able to trace spend to value, margin, or profit? Not really. It requires deep customization and a clear understanding of your cost model. And most teams just aren’t there yet.”
The result is FinOps teams are busy, leaders are asking for proof, and no one’s quite convinced the value is there.
From cost tracking to business alignment
To move beyond dashboards and daily operations, teams need to reconsider how they define—and demonstrate—impact.
Here are four patterns we’ve seen in teams making real progress:
1. Treat operational basics as non-negotiable
If tagging is still best-effort, if forecasting isn’t enforced, if cost allocation is inconsistent, then you don’t have the foundation to show value. These aren’t simply best practices—they are the price of admission.
2. Measure outcomes, not just spend
What does cloud success look like for product, finance, or engineering? If your metrics don’t connect to things like velocity, margin impact, or unit economics, you’re not telling a value story. You’re just listing expenses.
3. Translate goals across stakeholders
FinOps doesn’t prove value in a silo. It has to connect across engineering, finance, and leadership—bridging what each function sees as success and identifying shared outcomes everyone can support.
4. Track lead time from signal to action
Insight-to-action lead time is one of the clearest indicators of both maturity and impact.
As Kyle said in the webinar: “Insight-to-action lead time is a trackable metric that helps realign the business around current-state reality and where we can actually move the needle—and it keeps both sides honest.”
If your dashboards are full of savings opportunities, but nothing’s getting implemented, you don’t have an optimization problem—you have an execution one.
Ready to declare ROI? Ask yourself:
- Can we clearly articulate the business outcomes we’re aiming for?
- Do our metrics reflect value not just cost?
- Are our tagging, forecasting, and allocation strategies enforced and trusted?
- Can stakeholders see the impact of FinOps without needing a translator?
If those answers aren’t solid, don’t be too hard on yourself. At least you’re now seeing the gap more clearly, and clarity is what opens the door to progress.
Where FinOps goes from here
FinOps has come a long way. The frameworks, tools, and organizational buy-in are there. But cloud ROI is still the missing link between operational effort and strategic influence.
The teams that will stand out in this next phase won’t be the ones with the flashiest dashboards. Instead, they’ll be the ones who slow down when it counts, close the loop on fundamentals, and stay relentlessly focused on business outcomes.
After all, confidence is great, but capability is what delivers.
Download the full 2025 CloudBolt Industry Insights Report to explore the findings that inspired this series.
Part 2 of our Inside the Execution Gap series
Ask any FinOps leader where they stand on automation, and you’ll probably hear a confident answer.
In the 2025 CloudBolt Industry Insights (CII) Report, 93% of senior IT leaders said they’re using automation for cost optimization. At first glance, it sounds like a win.
But the data tells a different story.
- 65% said at least 20% of optimization recommendations go unimplemented.
- Most teams still take weeks or longer to remediate waste—even with automation in place.
- And outside of routine shutdowns, few are optimizing more complex workloads at scale.
So why aren’t those automation investments delivering results?
In Part 1 of this series, we explored the risks of expanding FinOps scope too soon. Here in Part 2, we unpack the difference between perceived automation and actual optimization—and why so many teams are still stuck in what we’re calling the automation illusion.
Everyone Says They’re Automated. Few Actually Are.
When we asked IT leaders whether their organizations use automation for cloud cost optimization, the answer was a near-unanimous yes.
But when we dug into what “automation” actually meant, the scope narrowed fast.
- Shutdown schedules and idle resource cleanup were by far the most common.
- Kubernetes rightsizing, commitment-based discounting, and real-time remediation were far less prevalent.
- And only a third of teams said they consistently automate purchasing decisions tied to optimization goals.
This disconnect reveals the problem: “automation” is being defined far too loosely—often as nothing more than scripted schedules or alert-based workflows.
As Tracy Woo, Principal Analyst at Forrester, pointed out in our recent webinar, Beyond the Dashboard: Why FinOps Must Evolve for AI, Automation, and Reality: “I have a lot of suspicion around what’s being labeled as automation. If you’re talking about scheduled shutdowns or idle resource scripts that still require a human to say yes, that’s not automation. That’s just orchestration. True automation means no manual intervention. The system should understand when resources need to be on or off—and act automatically, without someone approving it first.”
The Real Problem: Insight Without Action
The issue isn’t that FinOps teams lack data or tooling.
The insights are there. The dashboards are full.
But visibility doesn’t reduce spend. Action does—and that’s where the breakdown happens.
Most teams are stuck in a fractured two-step process:
- FinOps surfaces an opportunity (idle resource, misconfigured service, underutilized commitment).
- Engineering or operations re-validate the opportunity, re-prioritize it, chase down approvals…and eventually deploy a fix—often weeks later.
By the time a single optimization is implemented, the opportunity may have vanished—or the delay has cost the business thousands.
As CloudBolt CTPO Kyle Campost explained during the webinar: “The full insight-to-action loop—connecting waste signals all the way through evaluation, prioritization, and execution into production—is almost never automated. And that’s the disconnect. High-performing engineering teams measure deployment lead time in hours. But FinOps teams often wait weeks for changes to go live. That’s a gap wide enough to kill momentum—and real savings.”
What True Optimization Maturity Looks Like
To escape the automation illusion, teams need more than alerts and scripts. They need a system that closes the loop—and keeps it closed.
Here’s what that looks like in practice:
- Close the loop: Optimization doesn’t end at detection. It ends when the change is deployed in production.
- Measure lead time: Not alert-to-ticket. Alert-to-action. How long does it really take to fix an issue?
- Minimize approvals: Design trust boundaries that allow safe, repeatable optimizations to proceed automatically.
- Empower engineers: Give the teams closest to the code the visibility and autonomy to act—not just react to FinOps escalations.
Not sure where you stand? Start here:
- Are we automating action—or just creating better alerts?
- How long does it take to remediate waste?
- Can engineers fix cost issues without waiting on approvals?
If the answers are uncomfortable, that’s not failure. It’s clarity. And that’s the first step toward maturity.
Coming Up Next: Proving ROI
In the final part of this series, we’ll tackle the question that looms over every FinOps initiative: Are we actually proving ROI?
Because without clear, trusted links between cost optimization and business value, even the most efficient teams are flying blind.
Until then, download the full 2025 CloudBolt Industry Insights Report to explore all the findings behind the execution gap.
Part 1 of our series unpacking the 2025 CloudBolt Industry Insights (CII) Report
FinOps teams are feeling good. In our 2025 CloudBolt Industry Insights (CII) Report, 72% of senior IT leaders say they’re confident their FinOps practice is ready to take on new scopes like SaaS, private cloud, and AI. Nearly all respondents (96%) believe they’re at least moderately prepared.
It’s a promising sign of how far FinOps has come. But it also prompts a more sobering question:
Are teams actually ready to expand their scope…or just eager to?
When you look deeper into the data, confidence begins to blur. While there’s no shortage of appetite, many teams are still struggling to fully manage the scope they already have.
In this first post of our Inside the Execution Gap series, we’ll explore the disconnect between perceived readiness and real capability—and why jumping into new FinOps domains too early could undermine long-term maturity.
Confidence Is Rising. Capability? Not So Much.
Let’s start with the good news: FinOps has crossed the chasm.
Two years ago, when we ran a similar survey, most leaders were in wait-and-see mode. Leaders were cautiously investing in FinOps, still unsure if it would deliver real value. Today, there’s no debate—it’s working. FinOps has momentum.
But that momentum is pushing teams into more complex territory. The FinOps Foundation is expanding its framework to include SaaS, internal services, and on-prem environments. New working groups are tackling app rationalization, ITAM, and containerized workloads.
However, expansion is outpacing operational maturity.
In a recent webinar, Beyond the Dashboard: Why FinOps Must Evolve for AI, Automation, and Reality, we framed the conversation around three questions every organization should ask before expanding scope:
- Are we effectively managing our current cloud scope?
- Are we optimizing cost in practice not just in theory?
- Are we proving ROI from our cloud investments?
These aren’t theoretical. They’re readiness filters. And when applied to the CII Report data, they reveal a deeper gap between how teams feel and what they’re actually equipped to do.
We’re Still Struggling with the Core Scope
Start with Kubernetes.
It’s not new. It’s not niche. And yet 91% of respondents said they’re still struggling with Kubernetes cost management. Common issues included:
- Inconsistent optimization practices (49%)
- Poor workload-level allocation (33%)
- Inaccurate cost reporting
Meanwhile, 65% said over 20% of their optimization recommendations go unimplemented—and those that do often take weeks to complete.
These aren’t fringe problems. They’re foundational.
If teams are still stuck managing Kubernetes—which has been in the mainstream for years—how will they handle SaaS with opaque billing, private cloud with variable cost models, or AI workloads that spike unpredictably?
As Kyle Campos, CloudBolt’s CTPO, noted during the session: “The risk of not automating and optimizing these complex scopes far outweighs the risk of trying. That’s exactly why we’ve invested so heavily in solving it—not just allocating costs for things like Kubernetes, but continuously optimizing them as well.”
The Complexity Gap Is Widening
Expansion is inevitable. The question is how teams expand and whether they have the structure to support it.
Tracy Woo, Principal Analyst at Forrester, said it plainly: “We’re seeing FinOps teams take on app rationalization, on-prem software license costs, and even labor analysis. But the big question is are they doing it well, or just adding more responsibility without the support to handle it?”
In many orgs, FinOps teams are small (often 1–2 people) and overloaded. They report into different departments, react to anomalies, juggle tooling, and still get asked to deliver strategic business insights.
Piling on scope without support doesn’t just stretch capacity. It risks outcomes. Optimization slips. Allocations miss the mark. Confidence erodes.
Maturity First. Scope Second.
If you’re facing pressure to expand into SaaS, private cloud, or AI, this is the moment for a maturity check. Before diving in, ask:
- Do we have accurate, actionable visibility into our public cloud usage?
- Are we consistently closing the loop on optimization, especially in complex environments like Kubernetes?
- Do we have the telemetry and cross-functional engagement to support new scope areas?
- Are our tagging, forecasting, and commitment strategies truly embedded or still best effort?
- Will expanding scope improve business outcomes or just add more noise?
In Part 2 of this series, we’ll explore one of the biggest blockers to FinOps maturity today: the illusion of automation. Because often, the most advanced-sounding strategies fall apart in execution.
Download the full 2025 CloudBolt Industry Insights Report for more data and insights from today’s FinOps leaders.
Kubernetes can be hard to explain—especially to stakeholders who don’t live in YAML files.
But what if you could translate it into something your executives, engineers, and FinOps leads already understand?
At StormForge, now part of CloudBolt, one analogy that helps teams across engineering, operations, and finance align is this: running Kubernetes is like running an airline.
In the airline industry, something similar—called “yield management”—has long been used to optimize seat inventory and revenue through forecasting, overbooking, and flexible pricing.
You’ve got a fleet of airplanes (servers) and a steady flow of passengers (applications) trying to reach their destination. Your job is to keep the planes full, the passengers happy, and the costs low.
And just like airlines overbook flights based on probability and patterns, Kubernetes optimization isn’t about fixed capacity—it’s about intelligent bets, dynamic scaling, and data-driven decisions.
Let’s break down how this analogy works—and how StormForge fits in.
Part 1: The Basics of the Airline (Understanding Kubernetes)
Before we get into scaling strategies and optimization, let’s define the key moving parts of a Kubernetes environment through the lens of airline operations. These foundational terms help build a shared understanding—especially when you’re trying to align engineering, operations, and business teams.
Here’s how the main components of Kubernetes map to concepts everyone can visualize:
| Airline Term | Kubernetes Term | What It Means |
| Fleet of Airplanes | Nodes (Servers) | The machines in your cluster—big, small, cloud, on-prem, or hybrid. |
| Passengers | Applications (Pods) | The software and services you’re deploying. |
| Seats on the Plane | CPU & Memory | The fundamental compute resources each pod needs to run. |
| Gate Agent | Kubernetes Scheduler | The automated system that decides which app boards which server. |
This framework helps non-Kubernetes audiences get their bearings quickly. But just understanding who’s who in the airport isn’t enough—you still need a strategy for how to allocate resources, manage fluctuations in traffic, and prevent chaos during rush hour.
That’s where requests, limits, and autoscaling come in—and where many teams start to feel turbulence.
Requests vs. Limits: The Reservation System
This is the heart of the analogy—and the most common point of confusion for teams new to Kubernetes.
Resource Request = Your Guaranteed Seat
A request is like your confirmed airline seat. The Kubernetes scheduler won’t place a pod on a node unless it can guarantee the app has this much CPU and memory reserved. It’s the bare minimum the app needs to function.
Resource Limit = The Empty Seat Next to You
A limit is like stretching out into the empty seat beside you. You’re not entitled to that space, but if no one else is using it, your app can “burst” beyond its request for better performance. Once another pod needs the space, you shrink back to your assigned seat.
Most teams don’t get this balance right. They overestimate requests to avoid risk—resulting in bloated clusters, poor bin-packing, and higher cloud bills. Or they underestimate, only to find that a critical app can’t burst when traffic spikes.
In Kubernetes, setting the wrong requests is like blocking off entire rows on a plane “just in case.” You might think it’s safer—but you’re paying for a lot of empty seats. And that gets expensive fast.
The Safety Net: What If the Plane Fills Up?
The good news is, Kubernetes has a backup plan.
When too many passengers show up and the plane (node) is full, the Cluster Autoscaler steps in— like an airline calling in an extra plane from the hangar. Kubernetes spins up a new node, boards the extra apps, and keeps things running without delays or downtime.
But autoscaling only works well if requests are accurate. If every app is reserving more CPU and memory than it truly needs, Kubernetes will think it’s out of space and start adding nodes unnecessarily. That inflates costs—and introduces cold-start delays that can hurt performance for latency-sensitive workloads.
Autoscaling isn’t a silver bullet. It’s a safety net—but only if you know how to pack the plane efficiently in the first place.
Part 2: From Basic Airline to Optimized Operation
So far, we’ve covered the basics—how Kubernetes moves passengers around, reserves seats, and calls in extra planes when demand spikes.
The trouble is, most teams stop there. They run Kubernetes like a functional but clunky airline: good enough to fly, but not efficient enough to scale profitably.
But there’s a better way.
That’s where StormForge comes in—acting as the AI-powered operations center for your airline. It doesn’t just respond to incidents. It forecasts demand, tunes capacity, and helps your systems adapt automatically—before problems take off.
Two Ways to Handle a Surge in Passengers
When traffic spikes, there are two main options:
1. Vertical Scaling (Resizing the Seats):
You assign each passenger the seat size they actually need—no more, no less. In Kubernetes, this means tuning resource requests and limits for each app so they run efficiently without hogging space.
2. Horizontal Scaling (Opening More Check-In Counters):
Instead of resizing seats, you open more check-in desks. In Kubernetes, that’s Horizontal Pod Autoscaling (HPA)—adding more pod replicas to handle load in parallel.
Most teams rely on both. But when they’re not coordinated, things break down—fast.
Imagine this: one team is trying to reduce how much space each passenger gets to save room (that’s vertical scaling), while another team is simultaneously opening and closing more check-in counters to handle the crowd (horizontal scaling). Without coordination, the system starts reacting to misleading signals—creating chaos.
The StormForge Solution: A Smarter Operations Manager
StormForge helps you avoid that situation altogether—by making vertical and horizontal scaling work in harmony from the start.
Let’s say you know holiday traffic is coming. Here’s how StormForge responds:
“We’ve analyzed your historical traffic and forecast 500 passengers per hour. To handle this efficiently, we’ll set the ideal seat size (requests/limits) for each passenger and prepare to dynamically open 5 to 15 counters (pods) as needed.”
This coordination between request tuning and autoscaling leads to smoother performance, better efficiency, and fewer surprises.
So what exactly does StormForge do to make this all possible? Here’s the breakdown:
- Forecasts Passenger Flow
StormForge uses machine learning to analyze historical trends and forecast demand. For example, it might learn that your billing service consistently spikes on the first of each month—and prepare for that in advance.
- Tunes the Perfect Seat Size
It determines the optimal requests and limits for each app. Instead of setting 500m CPU just to be safe, StormForge may discover that 220m is the actual sweet spot—reducing cost while maintaining performance.
- Harmonizes Scaling Strategies
By aligning vertical and horizontal scaling inputs, StormForge eliminates the thrashing that happens when those systems operate in conflict. Your apps scale smoothly, predictably, and only when needed.
- Optimizes the Fleet
StormForge looks across clusters to evaluate server types and scheduling behavior. It helps you choose the most cost-effective mix of nodes—and ensures each one is utilized efficiently.
- Puts Operations on Autopilot
Once configured, StormForge continuously learns from new workloads. It automatically applies optimal settings to new apps as they’re deployed, within the guardrails you define. That means less time manually tuning YAML files—and more time building real value.
The Outcome: A Kubernetes Operation That Actually Works
By combining Kubernetes’ flexibility with StormForge’s intelligence, platform and SRE teams can unlock a new level of efficiency:
- Fewer Guesswork Mistakes
Engineers stop overprovisioning and start trusting data.
- Massive Cost Savings
You stop paying for empty seats. Clusters run at high efficiency without compromising uptime.
- Smoother Scaling
HPA and request tuning stop fighting each other. The system adapts as needed—with no firefighting.
- Better Executive Conversations
You can finally explain what’s happening in terms everyone understands—and show the ROI.
If you’re trying to make Kubernetes easier to manage—or easier to explain—remember the airline.
And if you’re ready to make it smarter, leaner, and more automated—that’s where StormForge comes in. Let’s talk.
See What StormForge Can Do
Request a demo
Quick take: The cloud management market is in flux. Platforms are converging, scope is expanding beyond core infrastructure, automation is becoming table stakes, and the VMware shakeup is forcing governance decisions sooner than expected. Buyers are increasingly demanding extensibility, agentless architectures, and vendor independence to avoid lock-in, overhead, and shifting product priorities. Analyst maps like the GigaOm Radar show which vendors are adapting fastest—and why that matters for leaders making platform bets today.
The cloud management market isn’t just progressing— it’s reshaping itself in ways that change how leaders think about their next move. Over the past year, we’ve seen HPE’s acquisition of Morpheus Data—while clearly aimed at bolstering GreenLake—highlight the ongoing tension between hardware-centric strategies and pure software innovation. IBM’s move to bring HashiCorp under its umbrella is another big swing: folding Terraform and Vault into a larger automation portfolio signals intent, but whether that accelerates innovation or gets buried in a massive enterprise stack remains to be seen. And then there’s the VMware ripple effect. Broadcom’s changes are prompting organizations to reevaluate their control planes, governance models, and long-term vendor strategy. For many, these decisions have moved from “sometime later” to “on the agenda now.”
At the same time, the FinOps Foundation’s release of FOCUS 1.2 brings SaaS and PaaS into scope, signaling that cost governance expectations are no longer just about cloud infrastructure. And in Kubernetes, automation continues to mature with EKS Auto Mode and Karpenter. But here, too, the story isn’t settled: autoscaling has never been easier, yet optimization—actually rightsizing the Kubernetes workloads—hasn’t scaled at the same speed.
These developments point to a larger reality: the era of narrowly focused tools is fading, but how vendors deliver breadth and adaptability is far from uniform.
When breadth becomes essential, the buying calculus shifts. It’s no longer just “Which tool solves this pain right now?” but “Can I trust large vendors—the ones that keep flipping strategies and priorities—to reliably underpin my IT operations?” And even breadth alone isn’t enough. What matters is extensibility: can the platform plug into the skills and tools your teams already use—Python, PowerShell, Bash—or does it lock you into proprietary languages and specialized developers?
In other words, this isn’t about patching today’s pain. It’s about choosing a platform you can trust to evolve with tomorrow’s disruptions.
Following the movement on the map
In the middle of this turbulence, analyst maps like the GigaOm Radar help visualize which vendors are leaning into these shifts versus struggling against them. The Innovation/Platform quadrant in particular is telling: it represents platforms that can orchestrate, govern, and optimize across complex hybrid environments while still adapting quickly.

That’s where CloudBolt appears in the 2025 GigaOm Radar for Cloud Management Platforms as a Leader and Fast Mover. The placement doesn’t mean every challenge is solved; it means the trajectory is clear. We’re moving with momentum in the direction the market itself is demanding: breadth, adaptability, and actionability. This positioning is particularly notable given the market consolidation—with some platforms shifting focus post-acquisition while others maintain their software-first innovation trajectory.
Being alongside the most capable platforms—and ahead of several well-known names in both breadth and maturity—matters because it validates the exact traits CMP buyers should be weighing right now:
- Converged capabilities that reduce tool sprawl without creating new silos.
- Optimization focus that prevents waste from simply scaling faster.
- Extensibility that respects your skills—Python, PowerShell, Bash, Terraform—instead of forcing specialized or proprietary languages.
- Agentless architectures that expand automation without piling on agents, overhead, or security exposure.
- Governance agility for a post-VMware reality where vendor strategy shifts are the norm.
- Vendor independence that prioritizes customer outcomes over hardware quotas or shifting M&A agendas.
What leaders should take from this
If you’re making platform bets in 2025, the question isn’t “Who solves my problem today?” It’s “Who’s positioned for the problems I can’t see yet?”
Beyond breadth lies depth. True platform value comes from integrations that adapt to your needs, not rigid connectors that force you into predefined workflows. When evaluating platforms, ask: Can I customize this ServiceNow integration to match our ticketing process? Can I modify automation workflows without waiting for vendor updates? The difference between “checkbox integrations” and truly extensible connections often determines long-term success.
The current market map—and our own placement within it—suggests four non-negotiables for CMP decision-makers:
- Choose breadth you’ll actually use: integration breadth is meaningless if it doesn’t translate into operational simplicity.
- Demand extensibility, not lock-in: your teams should build with the tools they already know, not learn proprietary languages to automate Day 2.
- Look beyond automation to optimization: efficiency gains come from smarter decisions, not just faster execution. Leading enterprises—including many Fortune 500s—are already rethinking their platform strategies on this principle, moving away from tools that scale quickly but wastefully.
- Treat governance as strategic insurance: in a shifting vendor landscape, control over your environment is a long-term asset. Especially critical when vendor acquisitions can shift product focus from customer needs to parent company priorities.
The market is speaking through actions, not just analyst reports. When organizations with 8+ year vendor relationships make switches, when enterprises choose platforms over their own parent company’s offerings, and when MSPs migrate their entire customer base—these aren’t anomalies, they’re indicators of where true platform value lies.
Download the 2025 GigaOm Radar Report or schedule a live demo to explore what this could look like for your organization.
At FinOps X 2025, one message echoed across sessions and conversations: FinOps is growing up. The scope is expanding. The tooling is maturing. And the community is more energized than ever.
But from our vantage point—both at the booth and through the lens of the 2025 CloudBolt Industry Insights (CII) report—a more complicated picture emerges. While the industry is talking about continuous optimization, full-stack accountability, and AI-powered action, the reality for most teams looks very different. Remediation is still slow. Manual workflows are still the norm. And too often, dashboards deliver signals that never turn into results.
That tension—between where the industry is headed and where most teams actually are—was the thread running through everything we saw. Here’s what stood out.
FinOps Scope Is Expanding—Whether Teams Are Ready or Not
One of the strongest themes at this year’s event was the broadening scope of FinOps. Conversations around SaaS optimization, internal service allocations, and cross-org chargebacks came up again and again. The FinOps Foundation even previewed new guidance to reflect this shift, including upcoming FOCUS updates to support hybrid and non-cloud services.
That expansion brings new complexity. Many teams are still building the foundations of tagging, anomaly alerting, and cloud governance—yet they’re now being asked to extend those practices to SaaS, business units, and internal tooling.
It’s a shift we’ve been anticipating at CloudBolt, where our focus has been on connecting cloud, SaaS, private infrastructure, and Kubernetes into a cohesive optimization model. That broader lens felt more validated than ever this year.
Small Teams, Big Expectations
One of the most consistent themes in breakout sessions: FinOps teams are small. Often just one or two people. And given current budgets, most aren’t expecting that to change.
To scale, organizations are adopting extended team models—like the “Friends of FinOps” program at Starbucks or “Efficiency Champions” at Reddit—where FinOps responsibilities are distributed across engineering, finance, and operations.
But even with this support, many teams described being stuck in time-consuming workflows that depend on human follow-up. What one panelist called “manual automation” felt like a shared pain point—where tasks are technically repeatable, but far from streamlined.
It’s a pattern we hear from customers as well, and one that reinforces why automation isn’t just a performance upgrade—it’s a necessity for sustainable FinOps.
Dashboards Are Better. But Action Is Still Slow.
FinOps X showed real progress in visibility tooling. Many vendors showcased slick dashboards, improved alerting, and stronger tagging hygiene.
But while these advances are meaningful, they don’t automatically close the loop. According to our 2025 CII report, 58% of organizations still take weeks or longer to act on cloud waste—even when the issue is visible.
That disconnect came up often in our booth conversations. Visibility has improved, but prioritization, approval flows, and execution still lag. Teams don’t lack signals—they lack capacity to act on them quickly.
That’s why we’ve focused on policy-based automation: helping teams define thresholds, evaluate risk in real time, and trigger actions without relying on manual follow-up. It’s not a silver bullet, but it meaningfully shortens the distance between signal and savings.
FOCUS Is Starting to Deliver on Its Promise
A year ago, FOCUS (the FinOps Open Cost and Usage Specification) felt like a rising standard. This year, it felt more like a movement. New contributors like Databricks, Alibaba Cloud, and Grafana joined in, and several sessions showed early examples of teams leveraging FOCUS for cleaner data and faster reporting.
There’s still work to be done, but the progress is encouraging. Standardized cost data isn’t just a win for reporting—it lays the groundwork for automation and cross-cloud analysis.
CloudBolt’s reporting framework already uses FOCUS to normalize usage across AWS, Azure, GCP, and OCI, and it was encouraging to see a broader push toward that same kind of interoperability across the industry.
AI Is Everywhere. Execution Still Isn’t.
AI was one of the most discussed topics this year—from anomaly detection to forecast modeling to GenAI-driven reporting. But most conversations, both onstage and off, focused on generating insights—not acting on them.
There was interest in real-time decisioning and automated remediation, but most teams admitted they’re still in early stages. Execution remains largely manual, and AI’s role is still emerging in day-to-day workflows.
That gap is something we’ve been working to close. Our approach to AI centers not just on smarter insights, but on helping systems respond—whether through policy enforcement, risk scoring, or embedded automation. There’s still a long way to go, but it’s a direction we believe the entire industry is heading toward.
SaaS Optimization Is the Next Frontier
SaaS stood out as one of the most talked-about challenges. As SaaS spend continues to grow, more teams are trying to apply FinOps principles beyond cloud infrastructure—and finding that visibility and control are often lacking.
Sessions touched on fragmented tooling, unclear ownership, and the difficulty of managing SaaS across business units. There’s a growing sense that the next wave of FinOps maturity will hinge on how well teams can bring SaaS into the fold.
That shift has come up more frequently in our own conversations, too. It’s why we’ve partnered with CloudEagle through our Technology Alliance Program—to help teams get a more complete picture of their SaaS usage and spending alongside their cloud environments. The goal is the same: better visibility, better accountability, and ultimately, better decisions.
It’s still early for a lot of organizations, but the interest is clearly growing—and the need is only becoming more urgent.
Final Thoughts
Last year at FinOps X, we described the event as a “home” for weirdos like us—practitioners working through the realities of adoption, evangelism, and scaling FinOps. That energy was still there this year, but it came with a new sense of urgency. The ambition has grown. So have the stakes.
But as our CII report shows, there’s still a significant execution gap. Even as the community rallies around advanced tooling and expanded scope, many teams are still working through foundational challenges. The desire to mature is real. The culture is taking shape. But the ability to act—quickly, confidently, and at scale—still lags behind.
That’s why we’re focused on building for that next phase. Because visibility matters—but action is what drives outcomes.
See How CloudBolt Turns Signals into Savings
Request a demo