VMwhere? How Enterprises Decide What Moves Off VMware and Where It Goes Next
Two years into VMware’s Broadcom era, most enterprises aren’t asking whether they are leaving. They’re trying to answer a more operational question. What can move safely this year, what has to wait, and what is realistically staying put for the foreseeable future?
Once you look at the estate workload by workload, the work breaks down into routing and sequencing. You have to match workloads to viable destinations, then order the moves so the organization can absorb the operating impact.
A key reason this stays messy is simple. There is no clean 1:1 replacement for VMware. VMware functioned as an operating model across compute, storage, networking, DR, tooling, and skills. When teams test alternatives, the constraints show up in the seams. That’s why plans get revised midstream even when the intent is clear.
What the data shows about how programs are actually moving
Our January 2026 research surveyed 302 enterprise IT decision-makers. The pattern is consistent:
- 63% changed strategy two or more times
- Only 4% report a completed full migration away.
- 41% say they’re staying with VMware while actively reducing dependence.
- 39% of migrating workloads are headed to public cloud IaaS, with Hyper-V/Azure Stack (38%) and Red Hat platforms (33%) trailing.
Most enterprises are spreading workloads across multiple destinations based on constraints. Public cloud absorbs what’s cloud-ready. Some workloads move to alternative stacks. Some get replaced with SaaS. Some remain where they are because the cost and risk of change is higher than the cost of staying in the near term.
For executives, the useful question is whether the organization has a repeatable routing approach and whether it can execute it without turning the mixed estate into sprawl. The hidden cost is opportunity cost. While teams run mixed-estate operations and a migration program simultaneously, other modernization work slows.
The five destinations most enterprises end up using
In practice, nearly every VMware transition program converges on the same set of destinations. The mix differs by enterprise, but the destination set is fairly consistent.
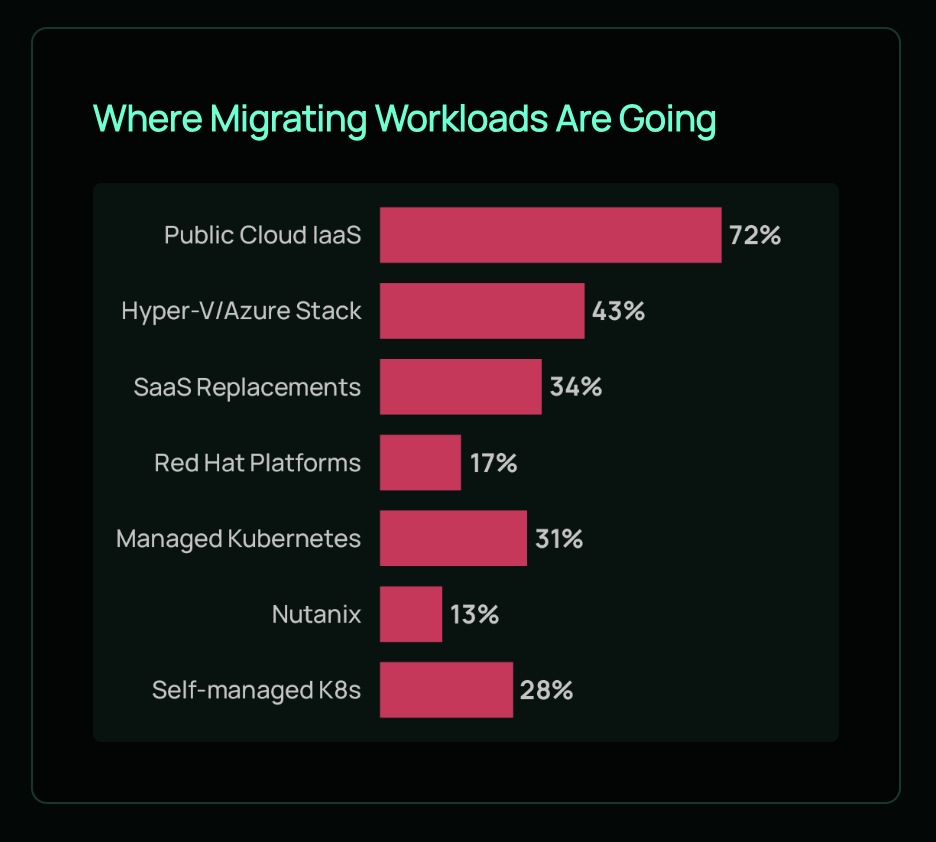
- Stay on VMware (stabilize + shrink)
- Rehost to public cloud IaaS
- Move to an alternative hypervisor or private cloud stack
- Replace with SaaS
- Refactor to Kubernetes or platform services
These choices aren’t just architectural. They change day-2 operations, including incident response, DR, patching, identity models, observability, and the skills required to sustain the destination.
A destination that looks cheaper on paper can cost more in practice if it increases operational complexity faster than the organization can absorb.
A practical routing matrix
You don’t need a complete model. You need shared decision logic that the organization can apply consistently.
Use this as a starting point. It’s a fast way to narrow down where something can go.
| Workload trait | What it usually implies | Likely destination(s) |
| Hard latency or on-prem dependency (plant systems, local integrations, specialized hardware) | Moving increases risk or breaks constraints | Stay (shrink), or alternative hypervisor/private stack |
| High dependency density (shared storage, brittle integrations, complex DR) | Sequencing and operating model matter more than platform choice | Often stay for now, paired with a deliberate carve-out plan |
| Cloud-ready and well-bounded (clear interfaces, manageable state) | Lower-risk candidate for rehosting | Public cloud IaaS |
| Commodity business capability (email, CRM, ITSM-class functions) | Replacement is faster than rebuilding. | SaaS replacement |
| Net-new builds (new services, new product lines) | Biggest leverage lever: stop growing dependence | Default to public cloud or Kubernetes/platform services |
| Strong platform maturity (standardized CI/CD, IaC, observability) | You can absorb architectural change without chaos | Kubernetes/platform services becomes viable sooner |
| Tight skills constraint (thin team, low tolerance for new ops burden) | Destinations that add operational surfaces will stall | Bias toward SaaS or the simplest viable rehost moves |
A concrete example: cloud-ready internal apps often re-home cleanly to IaaS, while tightly coupled legacy systems frequently stay in place until DR, identity, and operational tooling are ready to support a second platform.
The missing layer is sequencing
A routing matrix narrows the destination. Sequencing determines whether the program reduces renewal exposure or simply creates activity.
This is where transition programs either regain leverage or lose it. It’s also where leadership gets frustrated, because the program can look busy while renewal exposure doesn’t materially change.
Sequence work based on what improves leverage first, not what feels like the ideal platform outcome.
Three questions to pressure-test the sequence
- Leverage impact: If this moves, does it reduce renewal exposure in a meaningful way?
- Execution confidence: Can we do this without creating incidents or breaking DR requirements?
- Operational burden: Does this reduce operational drag, or does it add another platform surface that the team cannot yet support?
The next quarter’s sequence should be explainable in these terms without a lot of rationalization.
Some workloads won’t move soon, and that’s normal
Every program has workloads that won’t move quickly. They’re too interdependent, too regulated, too risky, or too expensive to re-architect in the near term.
That doesn’t mean the program is stuck. It means the program needs two tracks.
- Track A: Dependence reduction – re-home, replace, retire, or refactor what can change
- Track B: Stabilize and shrink – reduce risk and renewal exposure for what cannot move yet
The worst outcome is treating immovable-for-now workloads as a vague bucket. If you’re not careful, you will learn the painful truth of the old maxim “There is nothing more permanent than a temporary solution”—and that a makeshift solution is rarely the right one for the long haul.
Validation cycles that reduce uncertainty quickly
Destination decisions are hard for a reason. The constraints show up late, and the operational consequences are uneven across workload classes. The fastest way to get clarity is controlled learning.
1. The routing pilot (15 workloads)
Pick 15 workloads that represent your reality. Include easy wins, normal-hard, and high dependency.
Force a decision on each:
- likely destination
- blocking constraints
- required operating model changes
- estimated sequence and risk
Output: a routing policy grounded in evidence rather than preferences.
2. The net-new policy (60–90 days)
Decide where new workloads land by default.
This is the highest-leverage decision you can make quickly. Even if legacy takes years, you can stop expanding VMware dependence immediately. It also reveals whether the organization actually agrees on what diversification means in practice.
3. The DR and operations reality check
The hidden blocker in many moves isn’t compute. It’s how the workload is operated. DR orchestration, identity models, patching baselines, observability, incident response, and change control.
Inventory those requirements before you scale. If you skip this, you discover it mid-flight after the program has already lost credibility.
The report captures the lived version of this. Unwinding a decade of dependencies can take 18–24 months and is far more complex than a standard lift-and-shift. That complexity shows up most in operations.
What executives should demand to keep this from turning into sprawl
The best executive posture is to require clarity without demanding certainty.
Ask for:
- A one-page routing policy
How workloads will be classified and what destinations are in play.
- A sequencing rationale
Why the next quarter’s moves reduce renewal exposure or operational risk.
- Dual-ops guardrails
What will be standardized so the mixed estate doesn’t become chaos.
- Proof of dependence reduction
Not just counts of workloads moved—evidence that VMware footprint and renewal exposure are shrinking where it matters.
This is also where pressure becomes a forcing function. 41% report increased executive pressure since the acquisition. When routing logic is unclear, pressure doesn’t accelerate progress. It accelerates rework.
Teams tend to sustain progress only when provisioning and governance remain consistent across platforms, whether through process discipline, tooling, or a control layer that reduces duplication.
The practical takeaway
You don’t need to lock in a final destination for every workload on day one. You do need a repeatable way to route workloads to viable destinations, an approach that immediately prevents the VMware estate from continuing to expand, and a sequencing plan that reduces renewal exposure while the organization learns.
That is what keeps a VMware transition from turning into unmanaged dual-ops, while turning diversification into leverage rather than sprawl.
Read the full report: The Mass Exodus That Never Was: The Squeeze Is Just Beginning
Related Blogs

The VMware Decision Window: Waiting Is Getting More Expensive
Most enterprises did not respond to the Broadcom acquisition with a clean exit. In fact, they’re still working through their response, most often through phased…

