The Kubernetes Automation Trust Gap No One Talks About
The selective distrust of autonomous Kubernetes rightsizing, and how to overcome it.
Executive Summary
The CI/CD pipeline deploys code fifty times a day, and no one blinks. But ask the same organization to let automation right-size a Kubernetes workload, and suddenly things get real.
We surveyed 321 Kubernetes practitioners at enterprise organizations. They told us automation matters — 89% call it mission-critical or very important. They deploy code at speed without much debate. Then we asked what happens when automation tries to touch CPU and memory in production. What emerged was an industry that trusts machines to ship code but not to right-size the infrastructure running it.
They say they trust automation. But then they told us what they actually do when it comes to automatically optimizing Kubernetes.
They don't delegate. They review. They gate. They hesitate. And that's the tell.
But:
Trust here is conditional — and delegation to automation happens only when teams have guardrails, visibility, and rollback confidence.
What They Say: Automation Is Doctrine
Ask any Kubernetes practitioner if automation matters and the answer comes fast: Automation is not optional. It's part of the operating model.
Pipelines deploy constantly. Health checks fire automatically. Rollback happens without human intervention. This is an environment built on automation — and, on the surface, one that trusts it.
Automation Is Non-Negotiable
Q: "How critical is automation to modern software delivery in your organization?"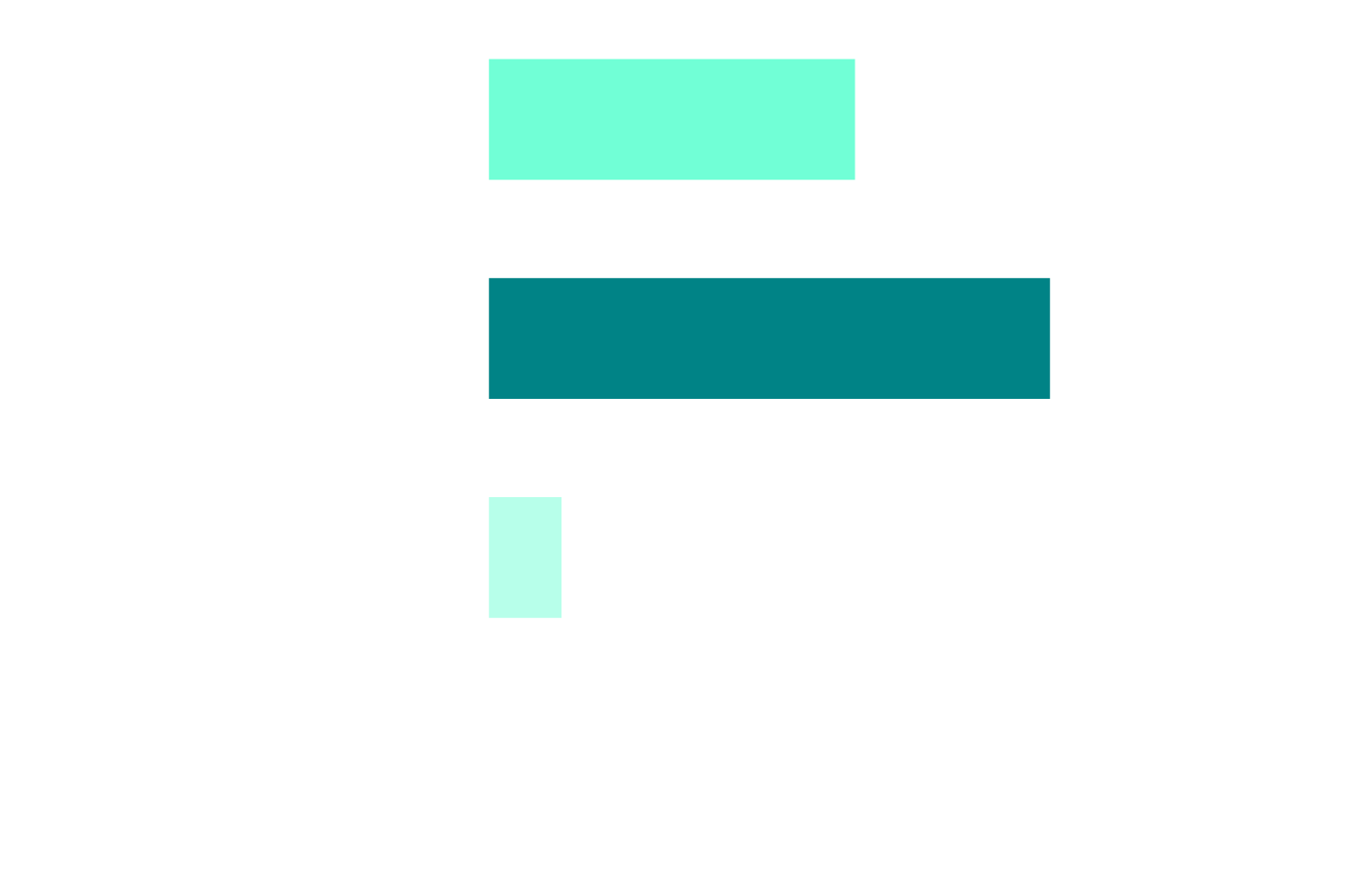
Delivery Trust Is Sky-High
Q: "To what extent do you trust automated delivery controls (e.g., tests, health checks, rollback triggers)?"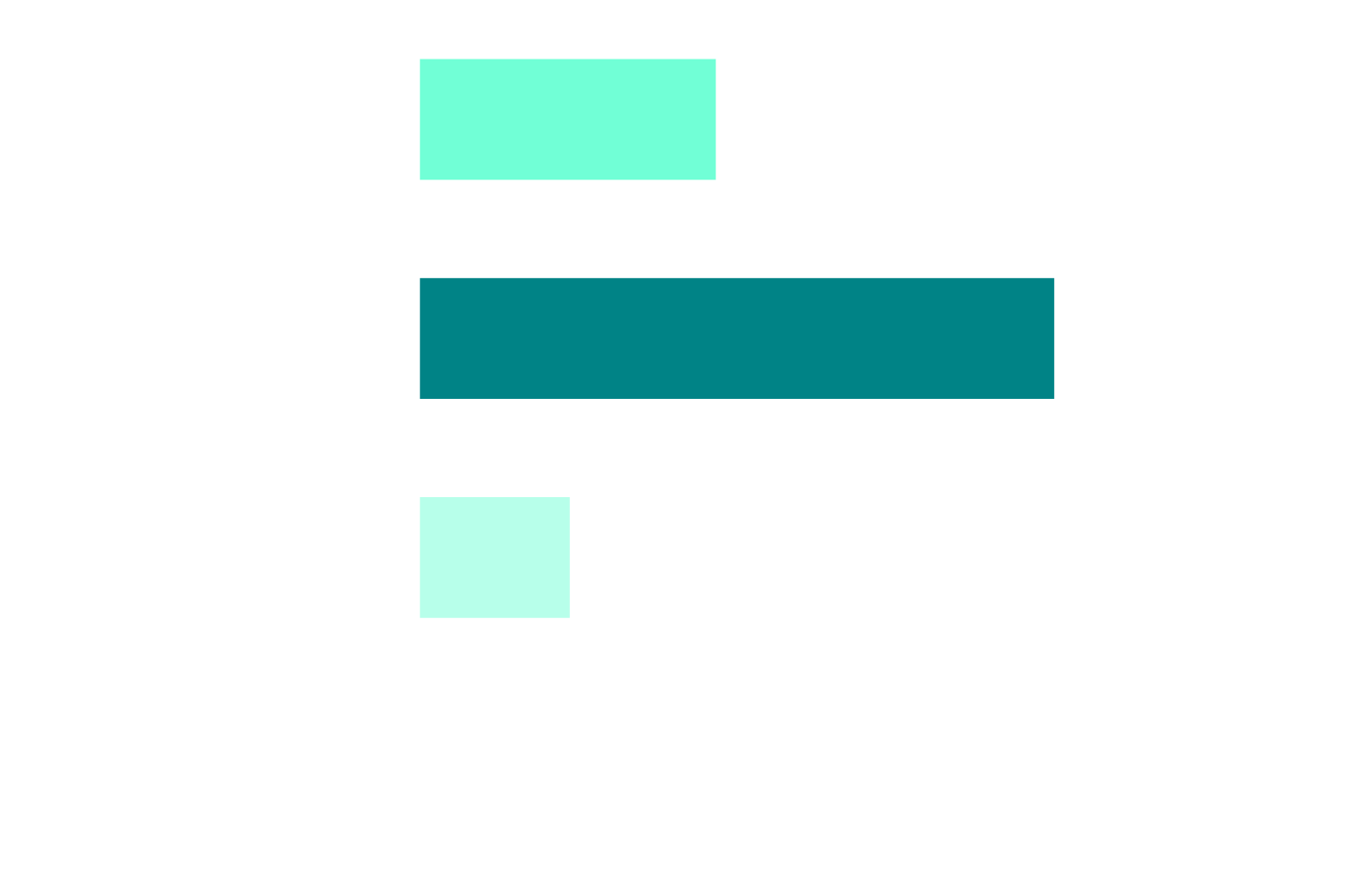
And yet…
What They Do: The Moment Trust Breaks
The shift is immediate once automation is asked to change CPU or memory in production.
That is where trust turns conditional.
Trust Is Conditional for CPU/Memory
Q: "To what extent do you trust automated delivery controls?" vs. "To what extent do you trust automation to adjust CPU and memory requests?"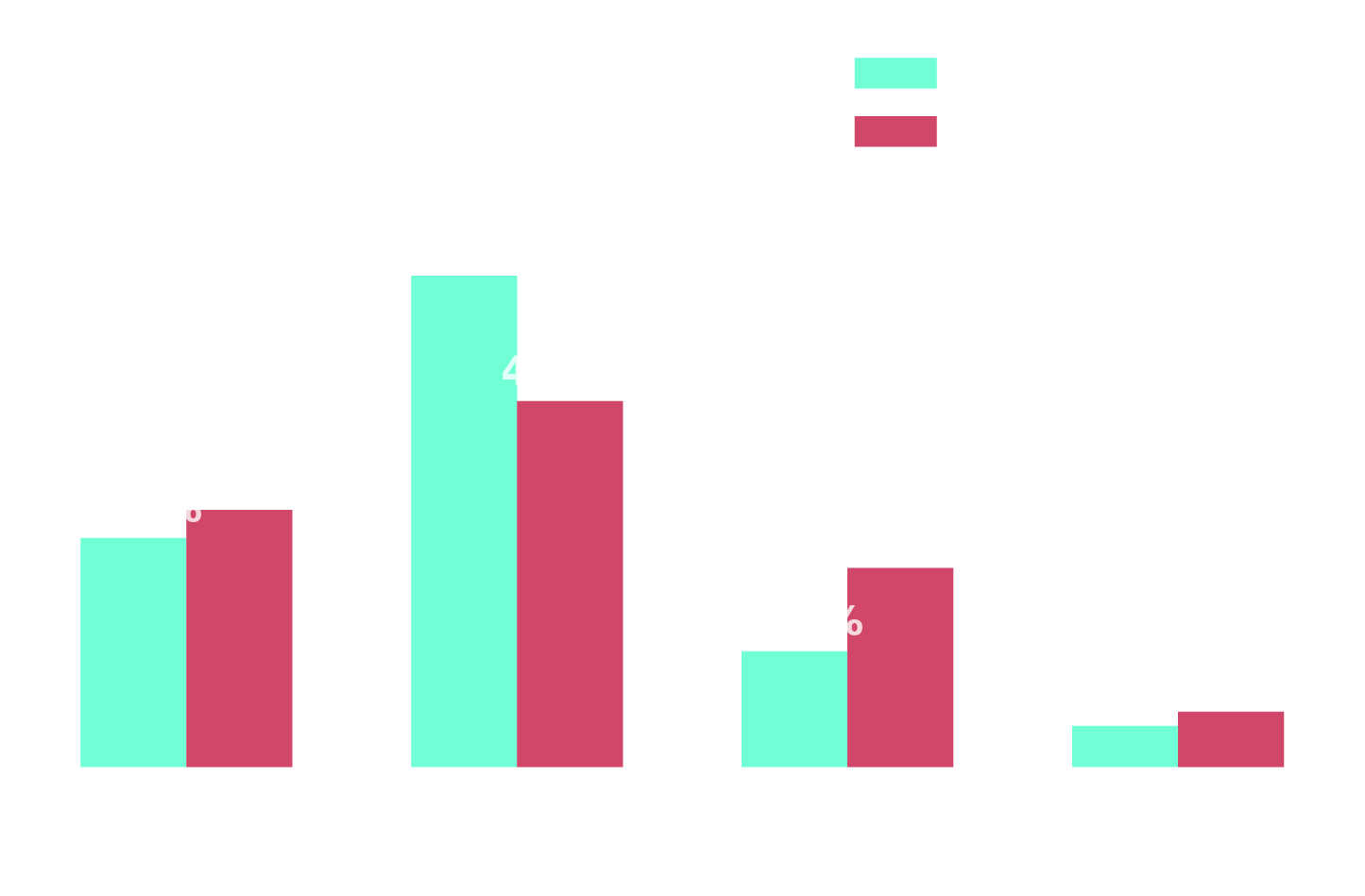
What Actually Happens to Optimization Recommendations?
Q: "If a system recommends reducing CPU or memory allocation for a production workload, what typically happens?"
This is not a rejection of automation. It is selective distrust.
If I can't see why it made a decision, I don't trust it. If I can't undo it cleanly, I won't allow it. And if it can't earn its way up from recommendations to guardrailed automation over time, it's just another tool my team has to babysit.
— Kubernetes Practitioner, 10–49 clusters
The same teams that routinely let automation ship code to production slow down when the change is CPU or memory. They review it, add guardrails, and want a rollback path they trust. Not because they distrust automation in general, but because capacity reductions can fail in quieter, harder-to-debug ways: rare spikes, cascading effects, and SLO drift that shows up only when it hurts.
What Delegation Reveals
When asked directly, most practitioners say they trust automation. But trust is not what people say. It is what they delegate. And in Kubernetes optimization, that delegation to automation still stops short.
If every action still needs approval, you have not really handed it over.
In production, I'm not optimizing for average utilization. I'm optimizing for resilience during the worst five minutes of the quarter. If a tool cannot prove it understands business criticality, SLO impact, and blast radius, I'm not handing it the keys — no matter how good the savings look.
— Kubernetes Practitioner, 10–49 clusters
The Paradox: High Belief, Low Delegation to Automation
This is where the contradiction becomes clear.
Even the teams with the lowest trust in optimization automation are still automating deployments at high rates.
Yet those same teams still manually gate optimization decisions. So this is not anti-automation behavior. It is something more specific.
They trust automation for change. But not for constraint.
Deploying code feels additive. Optimizing resources feels subtractive. One expands possibility, the other removes safety margin. And engineers know which one gets them paged at 3am.
The resistance is rarely technical. It is rooted in perceived risk. Constraint automation must earn more trust than expansion automation.
The Paradox in Action: Low-Trust Teams Still Automate Deployments
Cross-tab: Deploy automation frequency segmented by trust level in CPU/memory automation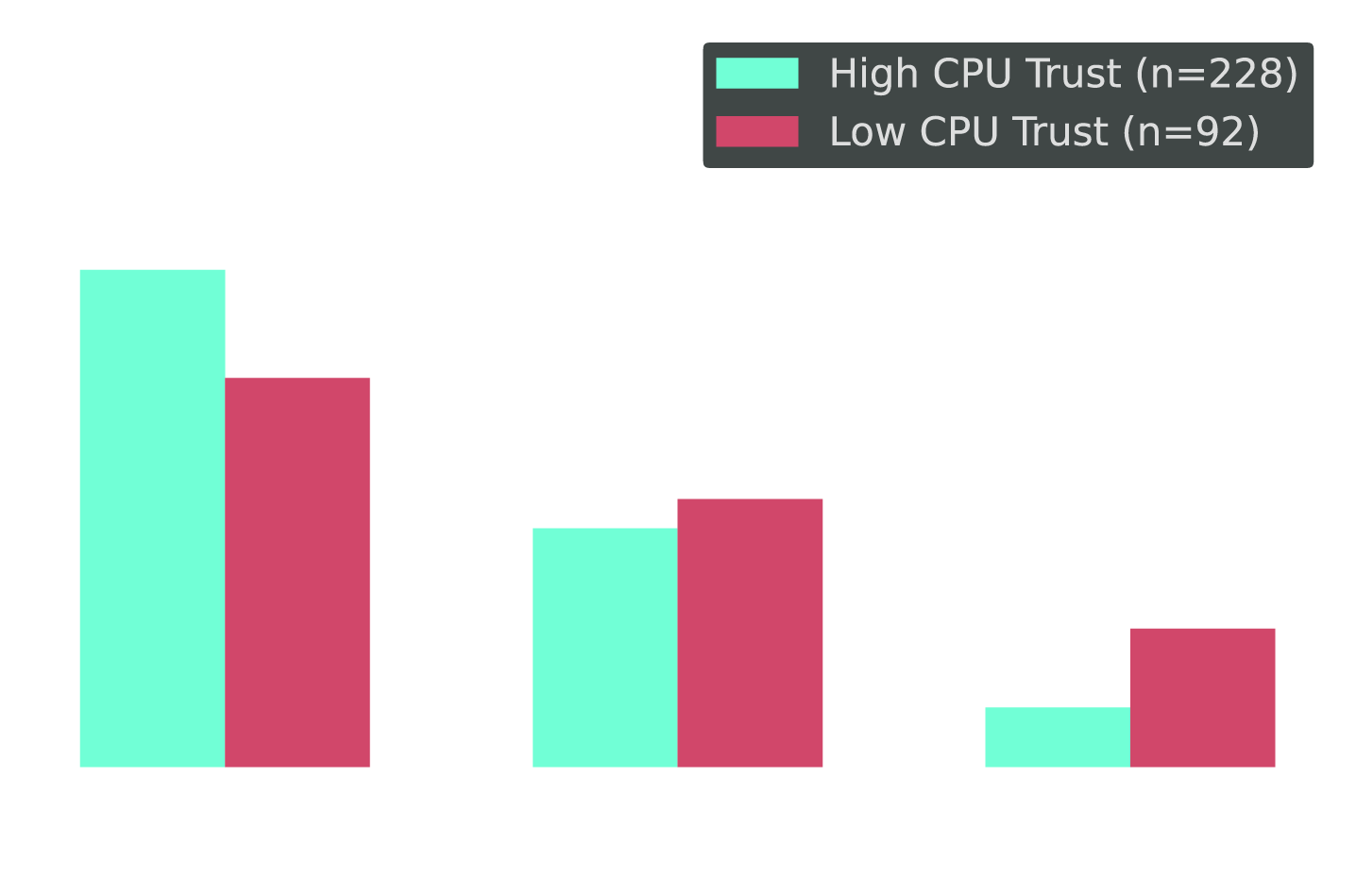
79% of Large Orgs Still Aren't Fully Automated
Cross-tab: Current optimization approach for organizations running 100+ clusters vs. fewer than 100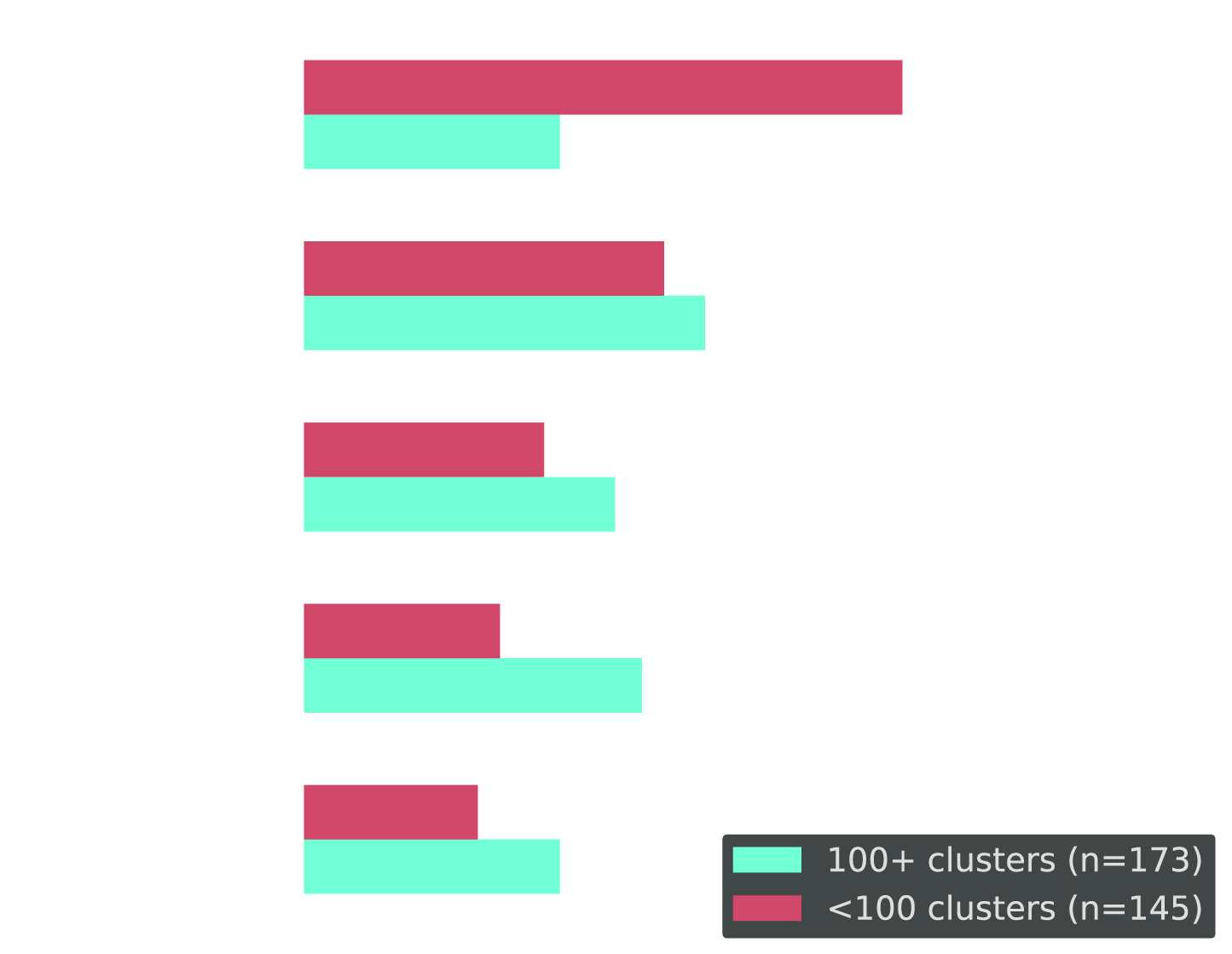
Scale Changes the Curve — But Delegation to Automation Still Lags
Cross-tab: % with High/Complete CPU trust vs. % auto-applied within guardrails, by cluster scale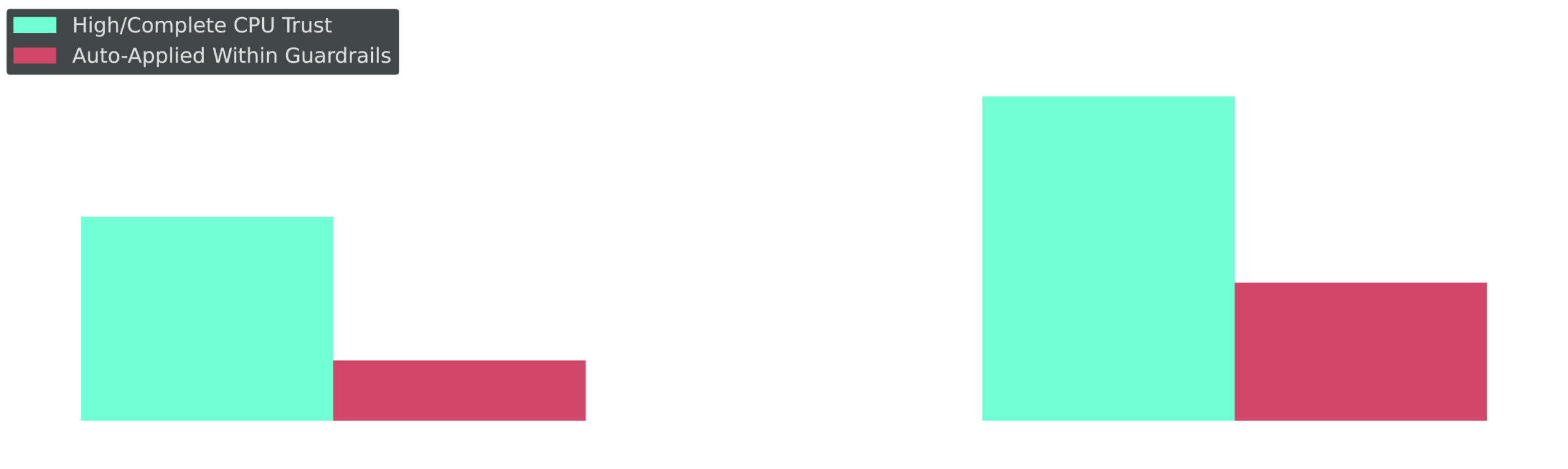
The Hidden Cost No One Measures
There is another cost underneath all of this, and most teams do not measure it. Teams are not optimizing for efficiency. They are optimizing for peace of mind.
The cost teams are protecting against is instability that has not happened yet. The fear of a production incident outweighs the reality of daily overspend. They knowingly over-provision infrastructure to avoid a failure that might happen. Because the cost of a hypothetical outage feels bigger than the cost of guaranteed waste. So they pay for that caution every day: in unused CPU, in excess memory, and in clusters that scale but never shrink.
The Why: This Isn't Irrational
This hesitation is not a failure of understanding. It is earned wisdom.
The engineers and SREs who pump the brakes on resource optimization automation have real reasons. OOM kills. Cascading failures. Previous-generation tools and models that confidently recommended "perfectly safe" changes — and were wrong. These are not hypothetical fears. They are failures teams have already lived through.
And exceptions rewrite behavior faster than success ever could.
A recommendation might be technically perfect, but if it touches a service owned by a team that had a major incident six months ago, that team is not touching their resource settings for a year — full stop. Vendors don't account for the human trust deficit, the ownership dynamics, the fact that an SRE has to go convince a skeptical engineering team that this number is safe. The last mile is a people problem, and vendors consistently pretend it doesn't exist.
— Kubernetes Practitioner, 10–49 clusters
What Vendors Fundamentally Misunderstand
Q: "What is one thing vendors fundamentally misunderstand about Kubernetes optimization in production?" (open-text, thematically coded, n=304)
Trust Gap by Role: Proximity to Production = Less Trust
Cross-tab: High/Complete trust in delivery vs. CPU/memory, by role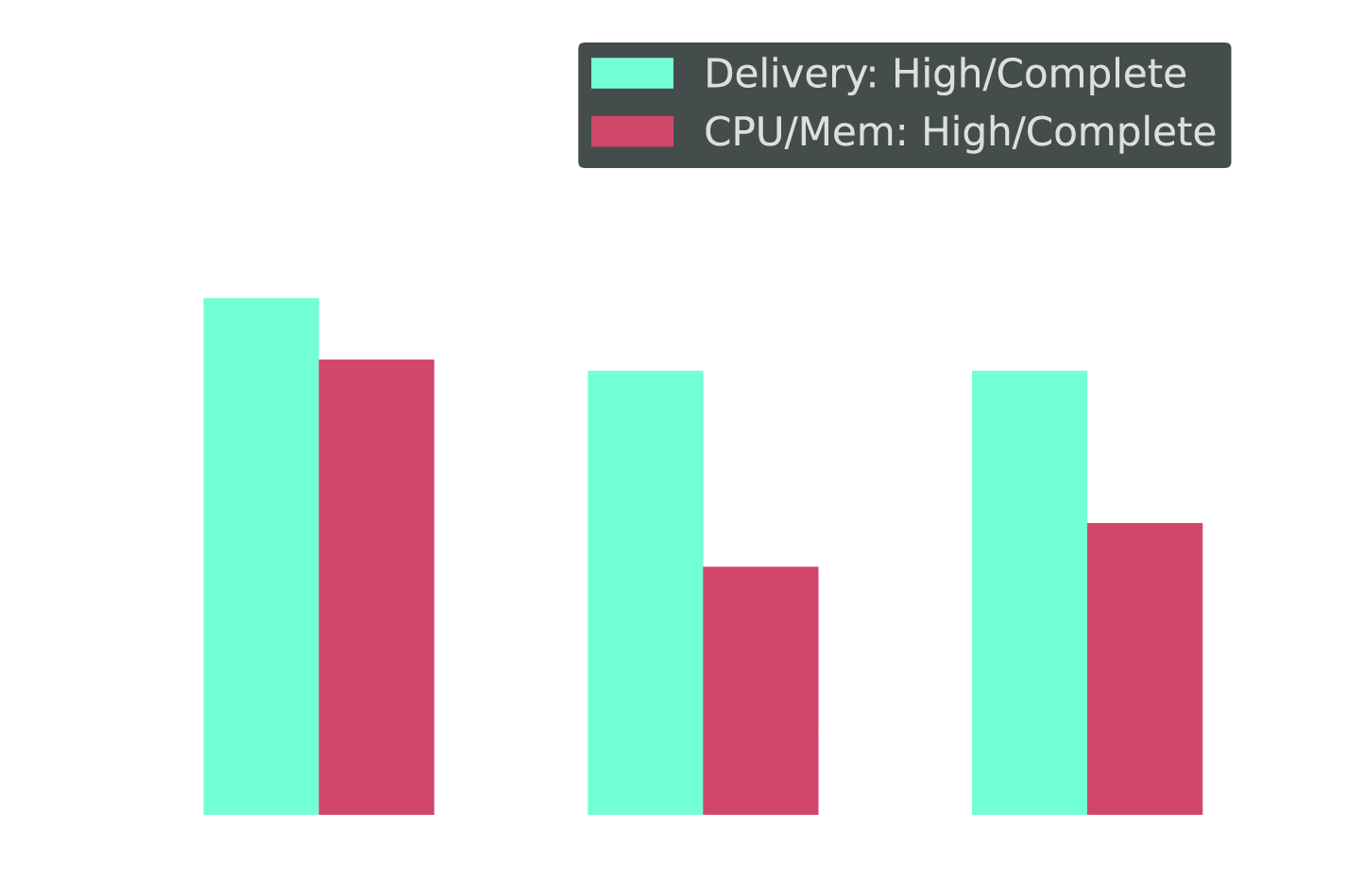
Engineers do not distrust Kubernetes optimization automation in theory. They distrust it in their environment, with their workloads, under their constraints.
It comes down to fear of breaking something that looks fine on the surface. A service can show low average usage all week, but then hit a traffic spike or weird edge case and suddenly that headroom really mattered.
— Kubernetes Practitioner, 10–49 clusters
Automated right-sizing carries a unique risk because it directly impacts the underlying stability of the application runtime. Unlike a code deployment that follows a tested path, resource changes alter the invisible contract between the workload and the scheduler.
— Kubernetes Practitioner, 500+ clusters
The Invisible Contract. Deploying code is visible. You know what changed. You can trace it. You can roll it back cleanly. Resource changes are different. They alter how Kubernetes schedules, prioritizes, and allocates — and that contract stays invisible until it breaks. That is why engineers who trust deployment automation still hesitate on resource optimization. The blast radius is different. The rollback path is different. And the consequences when things go sideways, are very real.
Trust Drops Closest to the Risk. The closer someone is to production, the less they trust. Executives show only a small gap. Platform and SRE teams show much larger ones. They're the ones holding the pager, and their accountability is on the line. Belief changes when accountability becomes personal.
Why the conditions may be changing. That caution was forged in a world of rigid rules-based automation and static algorithms. That world is changing fast. Practices that many teams even recently — AI-assisted code generation, AI-assisted operations, machine learning-driven decision making — are moving into the mainstream. Not because the skeptics were wrong to be cautious, but because the technology has started to catch up to the promise.
Vendors underestimate how risk-averse production teams are. Optimization isn't just cost reduction; it's balancing uptime, security, compliance, and performance under real traffic. Perfect math means nothing without operational trust and rollback safety.
— Engineering Director/VP, 500+ clusters
The caution was appropriate. The question now is whether it's still proportional — or whether a community that is embracing AI-assisted code generation may also be ready to trust AI-assisted resource optimization, given the right guardrails.
A Note for Practitioners
This is not a blame story. The trust gap exists for valid reasons, and much of that caution was earned the hard way. But this may also be the right moment to reexamine which assumptions still hold. The question is not whether the caution was justified. It is whether the conditions that created it still define the problem.
The Breaking Point: Scale vs. Human Control
The irony is sharp. The behavior that feels safest… doesn't scale.
The math is not close. It is off by orders of magnitude. At a certain point, manual review stops being caution and starts becoming a bottleneck.
Even High-Trust Teams Don't Fully Delegate
Cross-tab: Among High/Complete CPU trust only — what happens to recommendations? By cluster scale.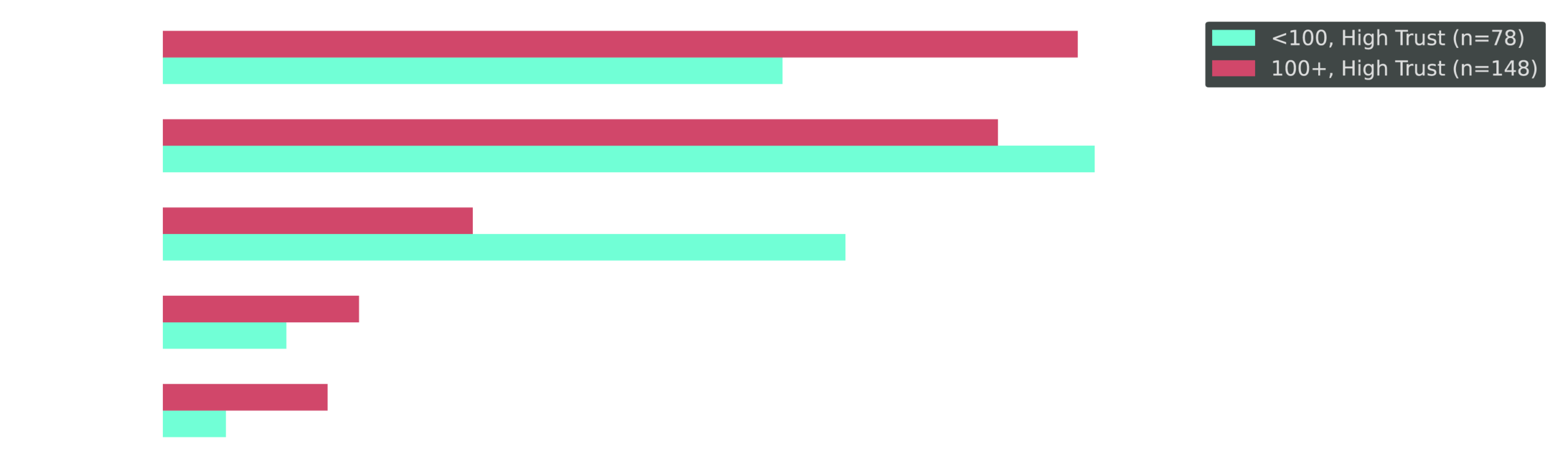
Code Moves Fast. Infrastructure Stays Frozen.
Cross-tab: Deployment speed vs. resource optimization speed (% at each frequency tier)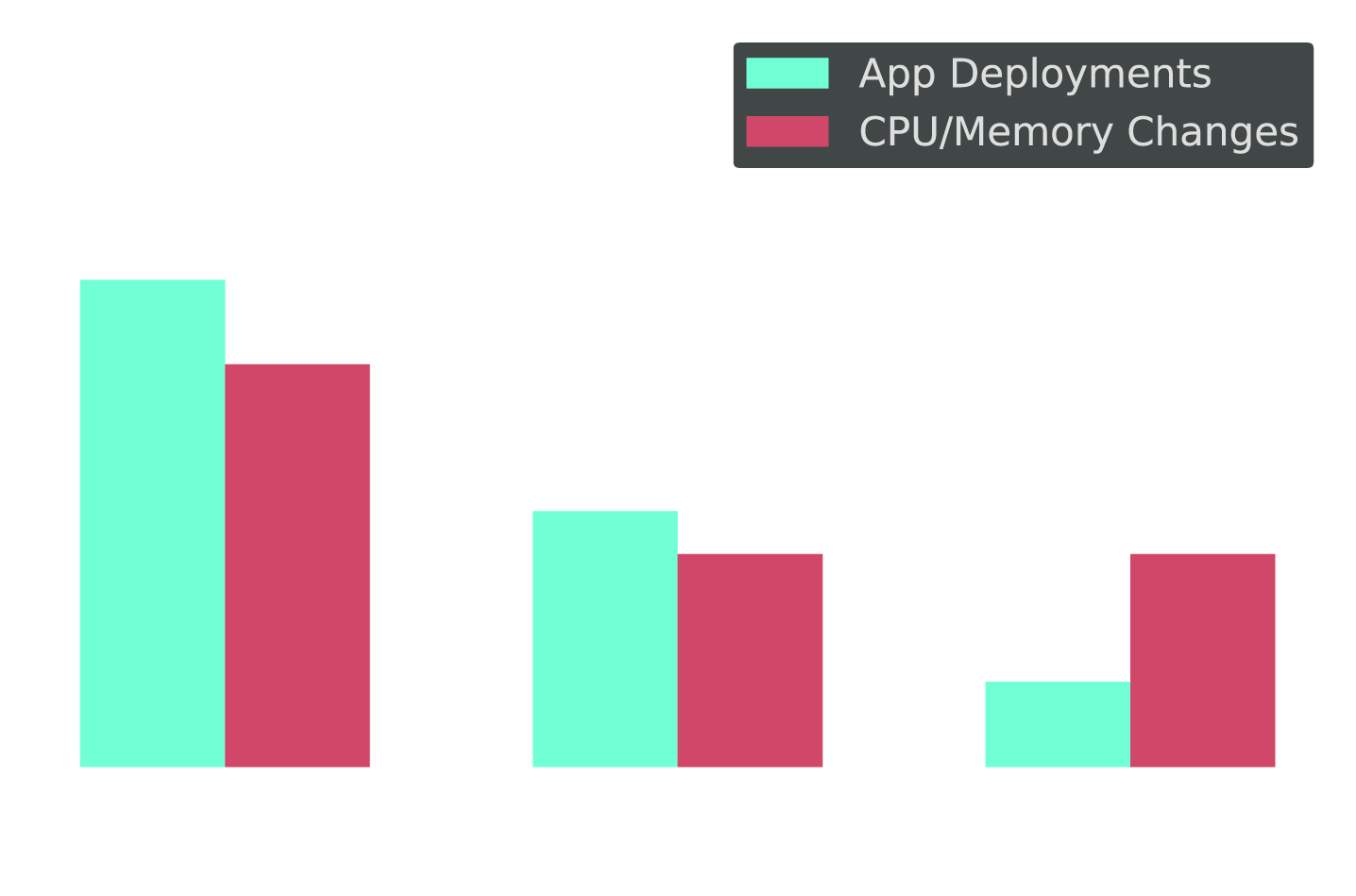
Current Approach: Most Teams Are Still Manual
Q: "How would you describe your current Kubernetes optimization approach?"
Cluster Scale Demands Automation
Q: "Approximately how many clusters are currently running on Kubernetes?"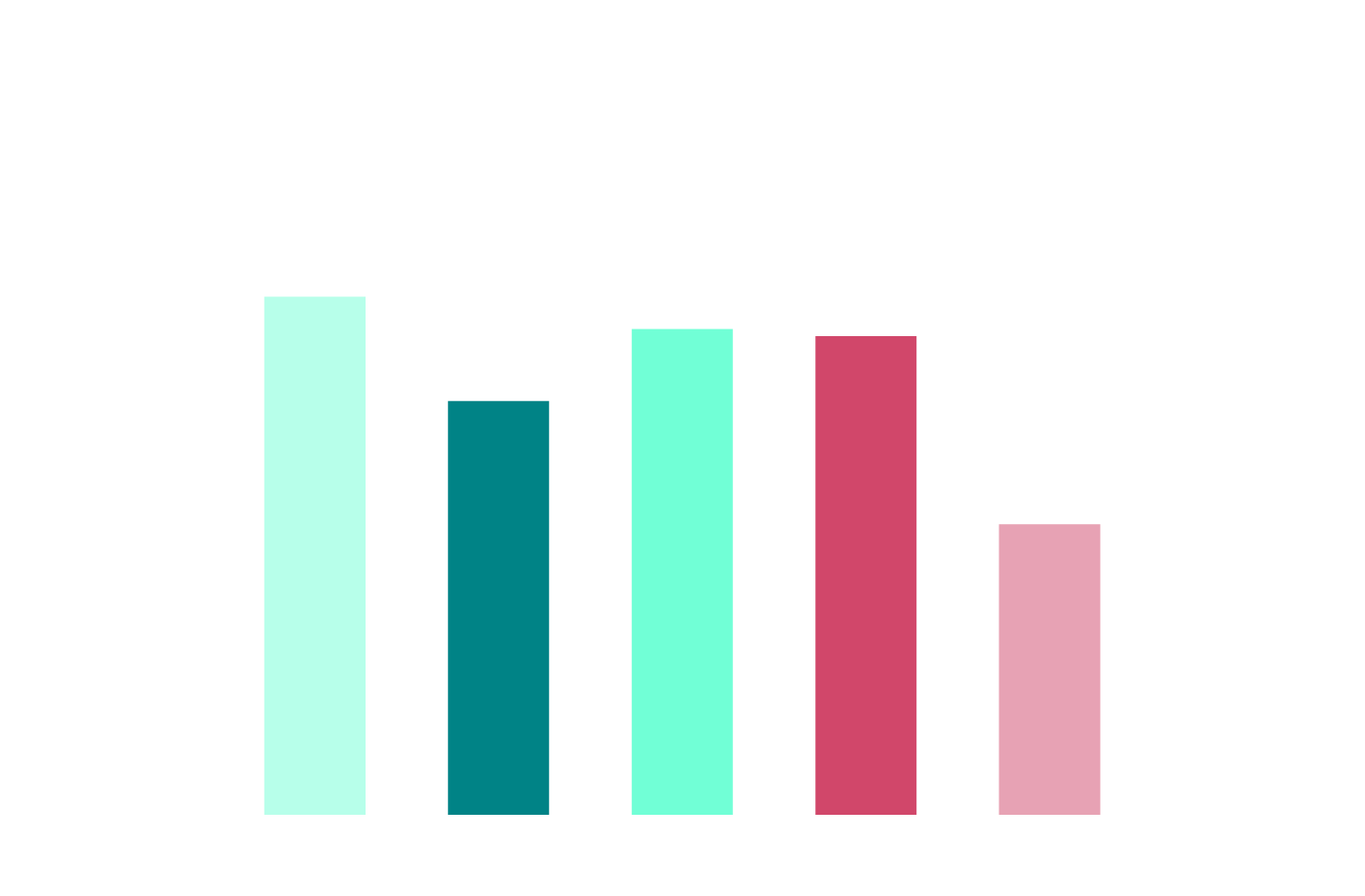
Where Manual Optimization Breaks Down
Q: "At roughly how many workload adjustments per day does manual right-sizing stop being practical?"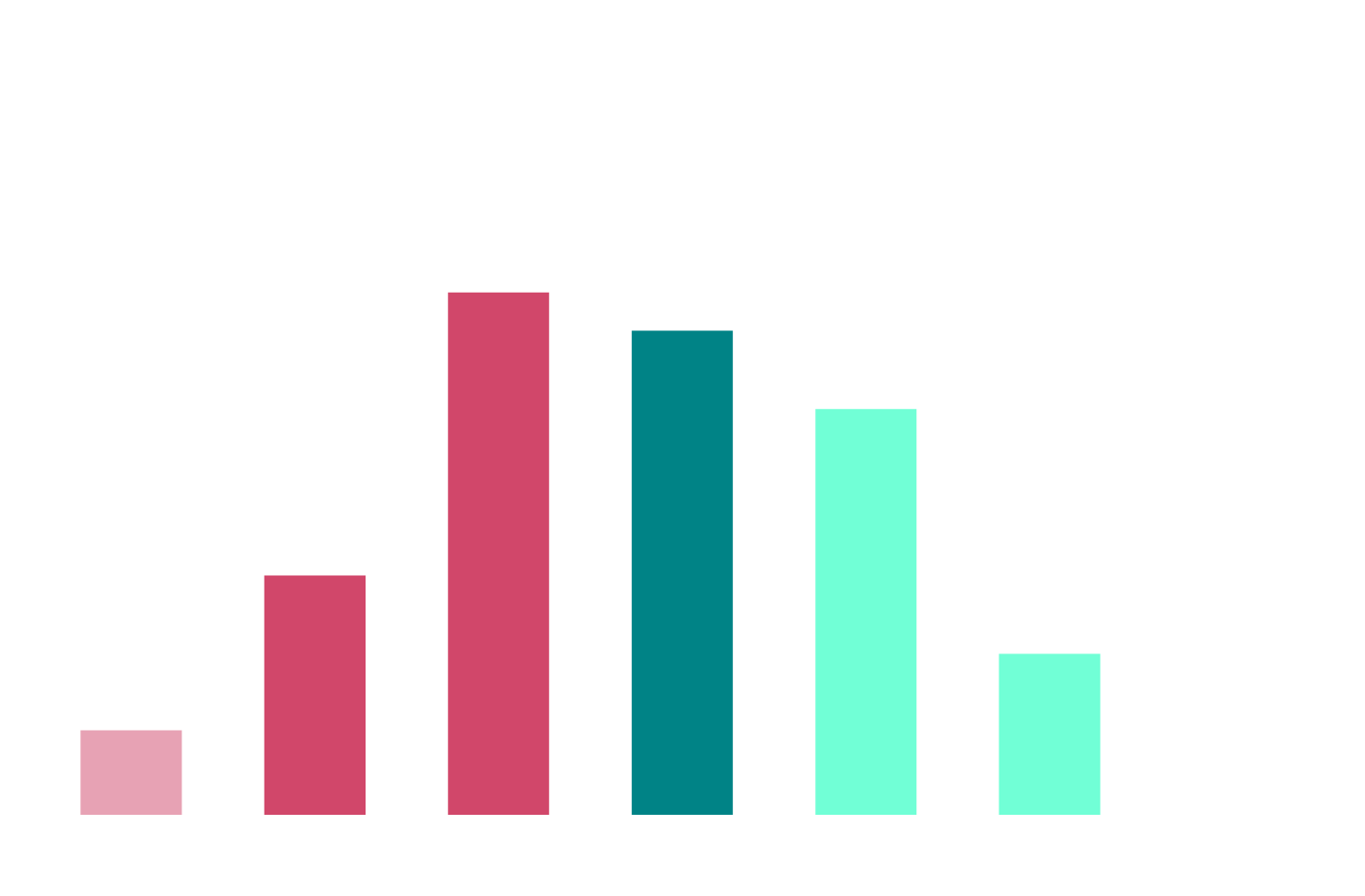
The progressive autonomy one resonates the most because it maps to how we actually build trust in any new system — you don't just flip a switch and go full auto, you earn it incrementally. Start with recommendations, let teams get comfortable, then graduate to guardrailed automation over time.
— Kubernetes Practitioner, 10–49 clusters
The Math That Breaks Manual
54% of respondents run 100+ clusters. At 50 pods per cluster, that's 5,000+ potential optimization decisions daily. But 69% say manual optimization breaks down before 250 changes per day. The gap between what needs to happen and what humans can review is orders of magnitude.
The Truth: This Is a Trust Gap — Not a Technology Gap
Vendors often treat this as a feature problem. The data suggests something else: it is a trust problem. And not the kind that shows up cleanly in survey sentiment. It shows up in the gap between what teams say and what they actually delegate.
This is not a gap that closes through feature checklists alone. It closes when teams see consistent behavior, clear limits, and safe rollback in production.
When you stop asking people whether they trust automation—and start asking what would increase that trust, the answers get much clearer:
The issue is not demand for more automation in the abstract. It is demand for safer, more legible automation.
What Would Actually Build Trust
Q: "What would most increase your trust in Kubernetes optimization automation?" (open-text, thematically coded, n=173)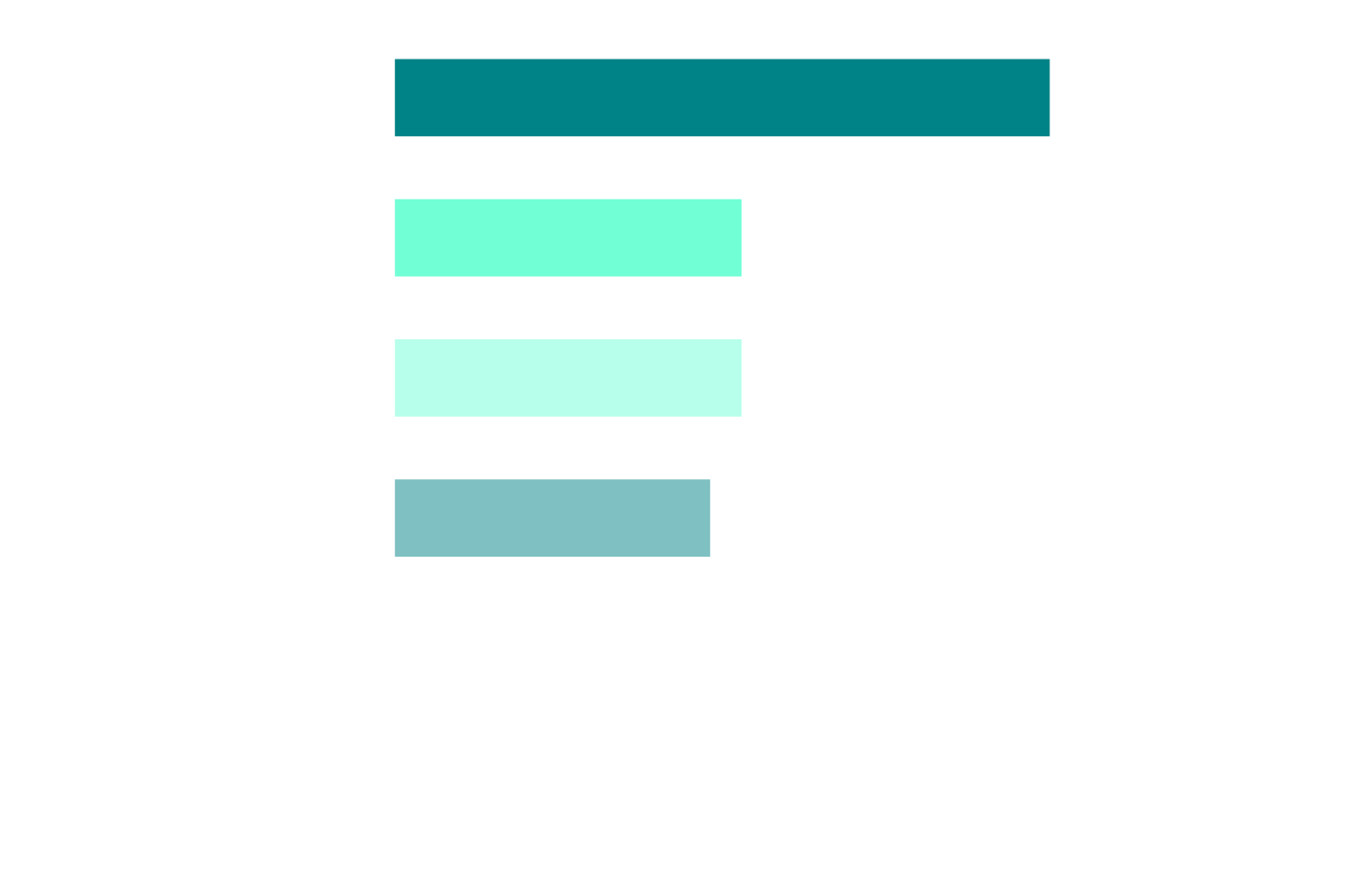
The Future They Want: Guardrails, Not Full Manual
Q: "How do you see the balance between human control and automation shifting?"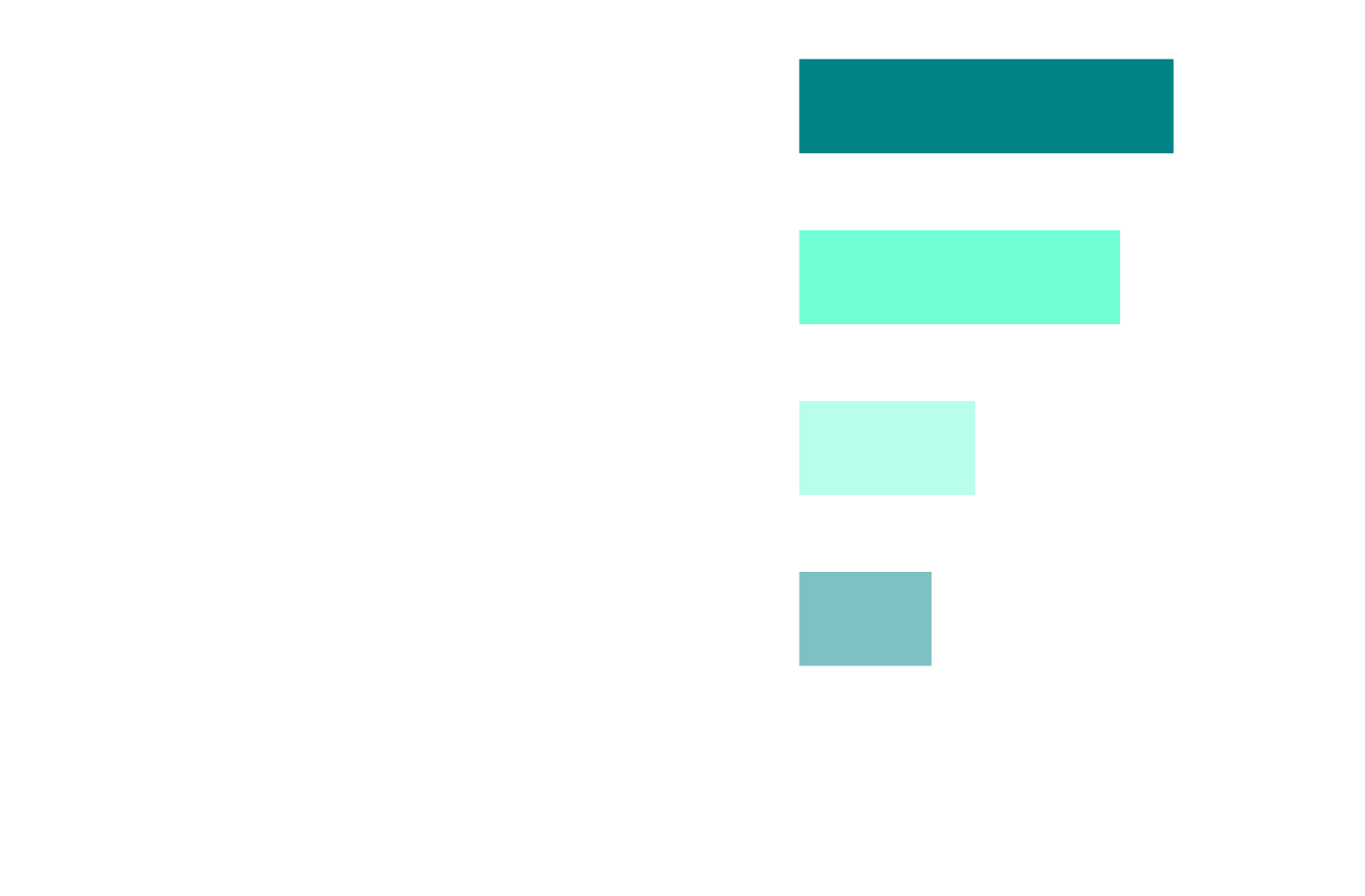
Even Manual Teams Want Guardrails
Cross-tab: Future optimization belief segmented by current approach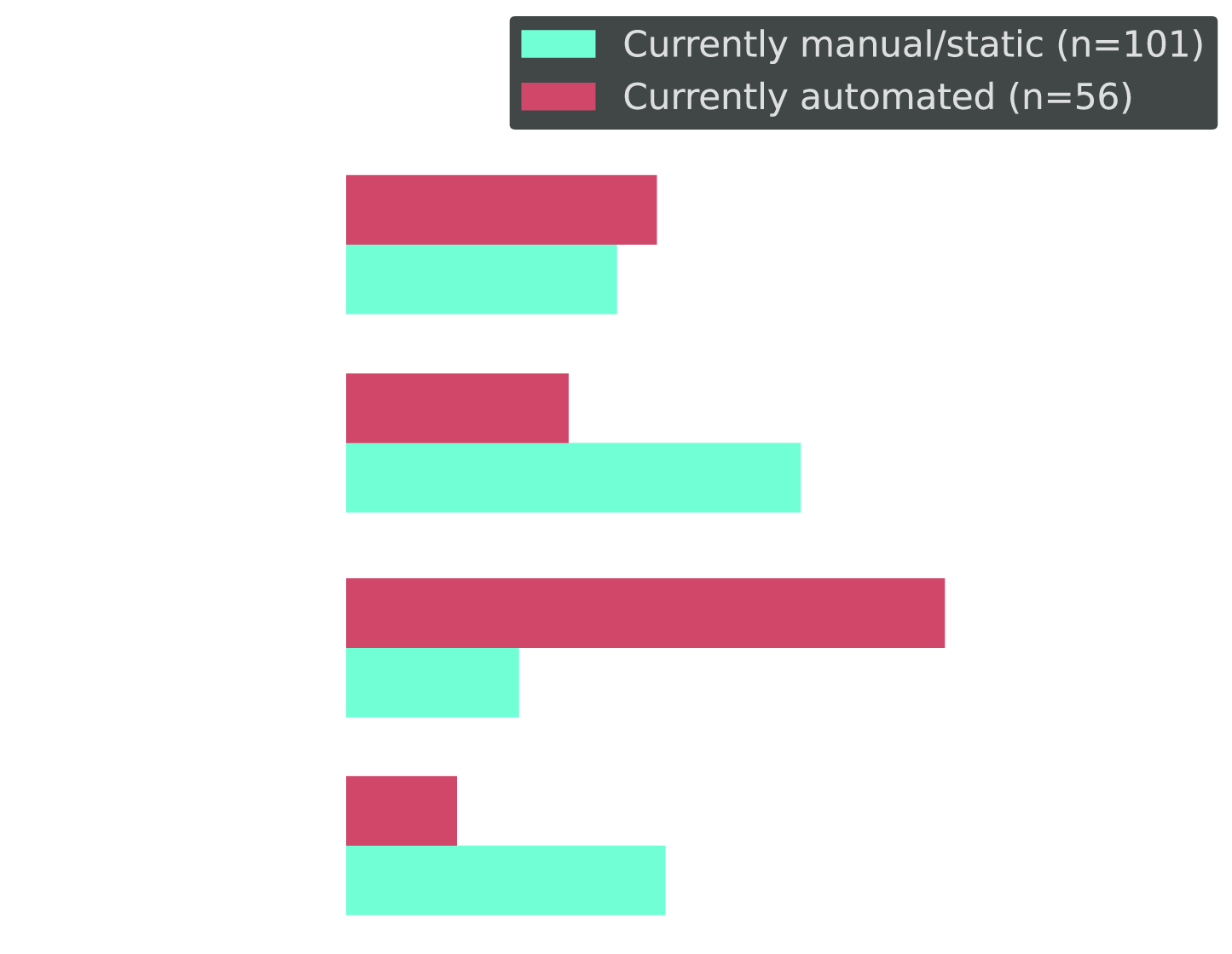
Trust Level Directly Determines Automation Adoption
Cross-tab: Current optimization approach by trust level in CPU/memory automation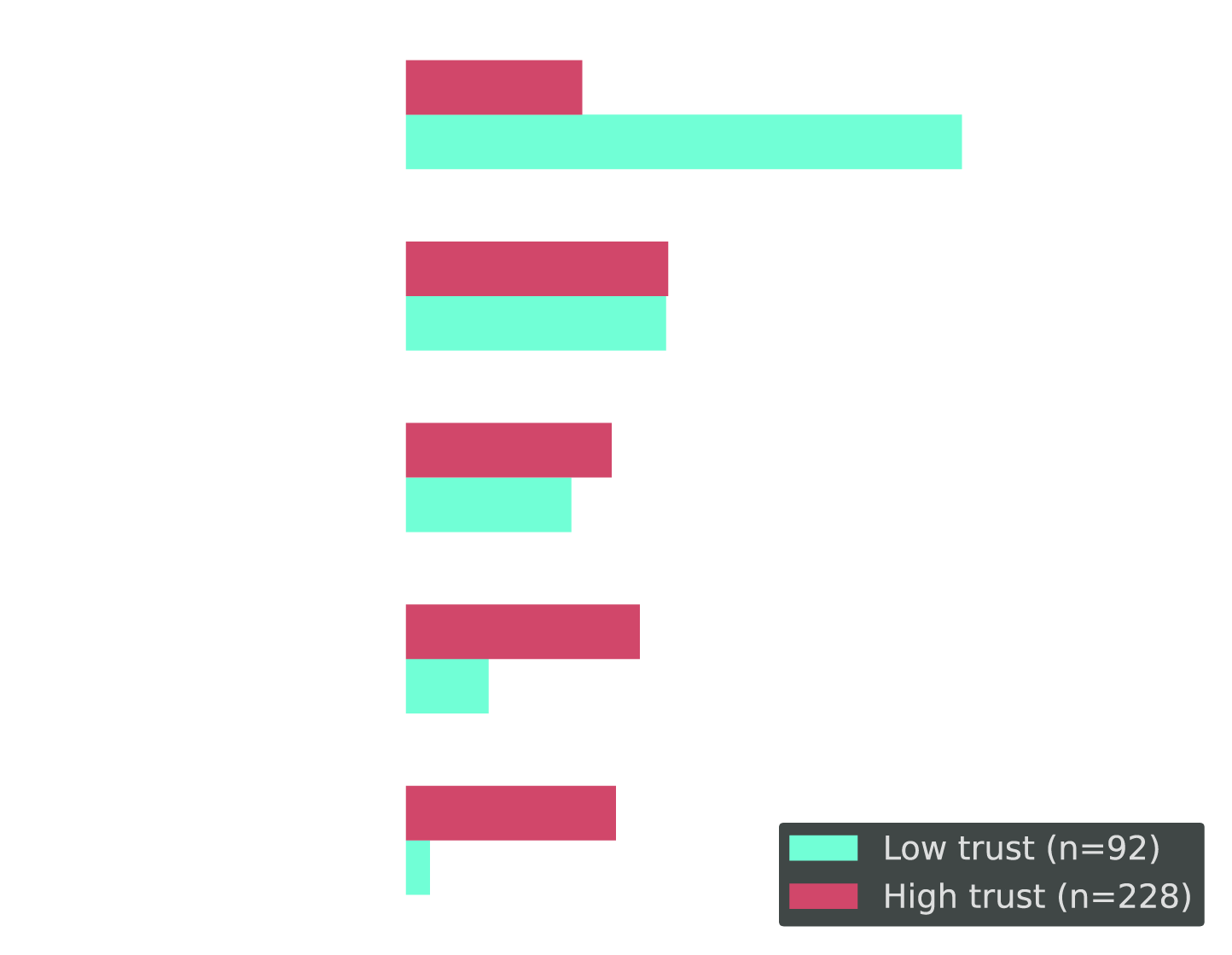
The Aspiration Gap
Cross-tab: Respondents wanting guardrails/autonomous future — what is their current approach?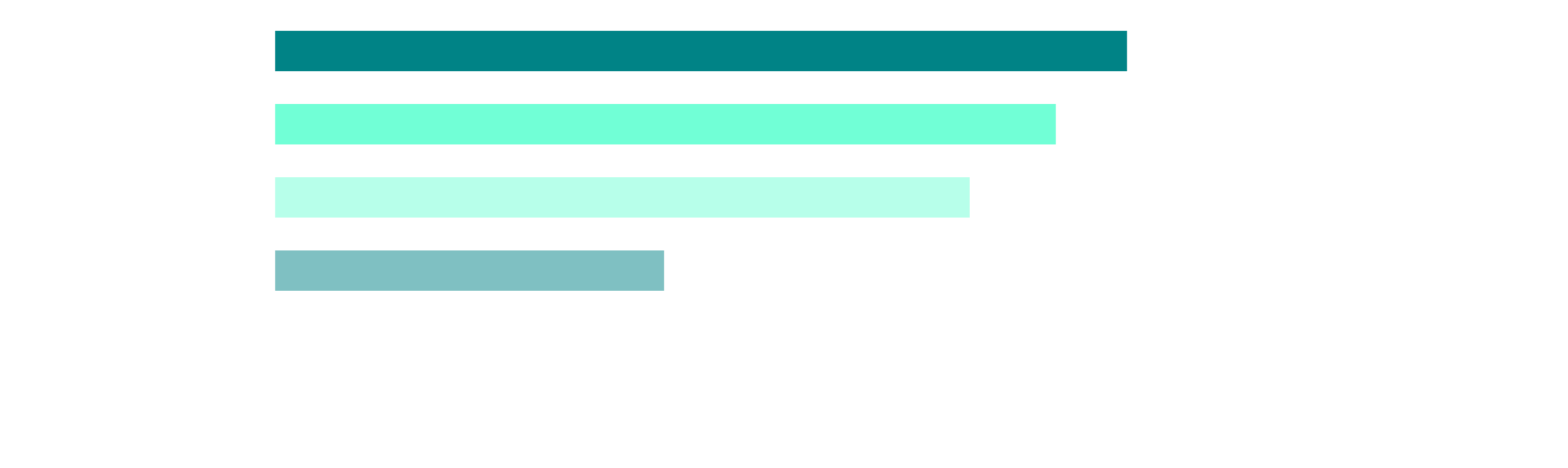
SLO-aware guardrails are huge for me. If automation can prove it will not violate error budgets or latency thresholds, that changes the conversation from cost-cutting to safe optimization.
— Kubernetes Practitioner, 10–49 clusters
The most significant increase in trust would come from a system that provides deep, contextual visibility into the decision-making logic alongside robust, automated rollback mechanisms.
— Cloud Infrastructure Leader, 100–249 clusters
What Teams Actually Want
No one is asking for full manual control and very few are asking for blind autonomy. They want something in between: automation with guardrails they can adjust over time as trust grows. The community isn't opposed to the destination. The destination is not the problem. The path is. Teams want a path that respects their operating reality, accounts for hard-earned caution, and gives them a credible way to expand trust over time.
The Trust Curve: From Recommendation to Delegation
Organizations do not flip a switch and arrive at trust. They build it step by step. That is why the path from recommendation to delegation matters more than any single claim of autonomy.
Today, most teams are still clustered around the first two levels. Recommendations-plus-human-decision and guardrails-plus-oversight make up roughly half of current approaches, while continuous automated optimization remains a minority state.
Prioritize reliability over maximum savings
Teams need to see that the system shares their priorities before they will share control.
Make Rollback Immediate and Visible
If it cannot be undone quickly, it will not be allowed.
Let trust expand in stages
Meet teams where they are and give them a credible path foward.
Design for the Human Decision Path
The SRE does not just evaluate the system. They often have to defend it to everyone else.
What Teams Still Need
If you ask teams whether they trust automation, many will say yes. If you watch what they actually delegate, the gap becomes obvious. Trust is not measured in sentiment. It is measured in what teams are willing to let run without them. That is the same behavioral gap the report establishes earlier between broad support for automation and much lower delegation of CPU and memory decisions.
In Kubernetes optimization, that gap is still wide, but the conditions are changing. The engineers and operators who built today's automation culture are also the ones best positioned to close it—not by abandoning their instincts, but by applying them to a safer, more transparent, more guardrailed generation of optimization tools. The trust is not missing. It is waiting to be earned.
Close the Trust Gap
CloudBolt's Kubernetes rightsizing is built for progressive autonomy: explainable decisions, SLO-aware guardrails, and instant rollback designed to help teams expand trust over time.
Explore Kubernetes Rightsizing →Methodology
This study was commissioned by CloudBolt Software, in partnership with Gather, to understand how enterprise Kubernetes practitioners are navigating the tension between automation ambition and operational trust in production resource optimization. The survey, conducted in March 2026, targeted 321 qualified Kubernetes practitioners — including Engineering Directors/VPs, Cloud Infrastructure Leaders, and Platform Engineering/SRE/DevOps Leaders — at organizations with 1,000 or more employees running production Kubernetes workloads. Open-text responses were thematically coded using keyword clustering; respondents may appear in multiple themes. Results are subject to sampling variation.
Respondent Roles (n=295)
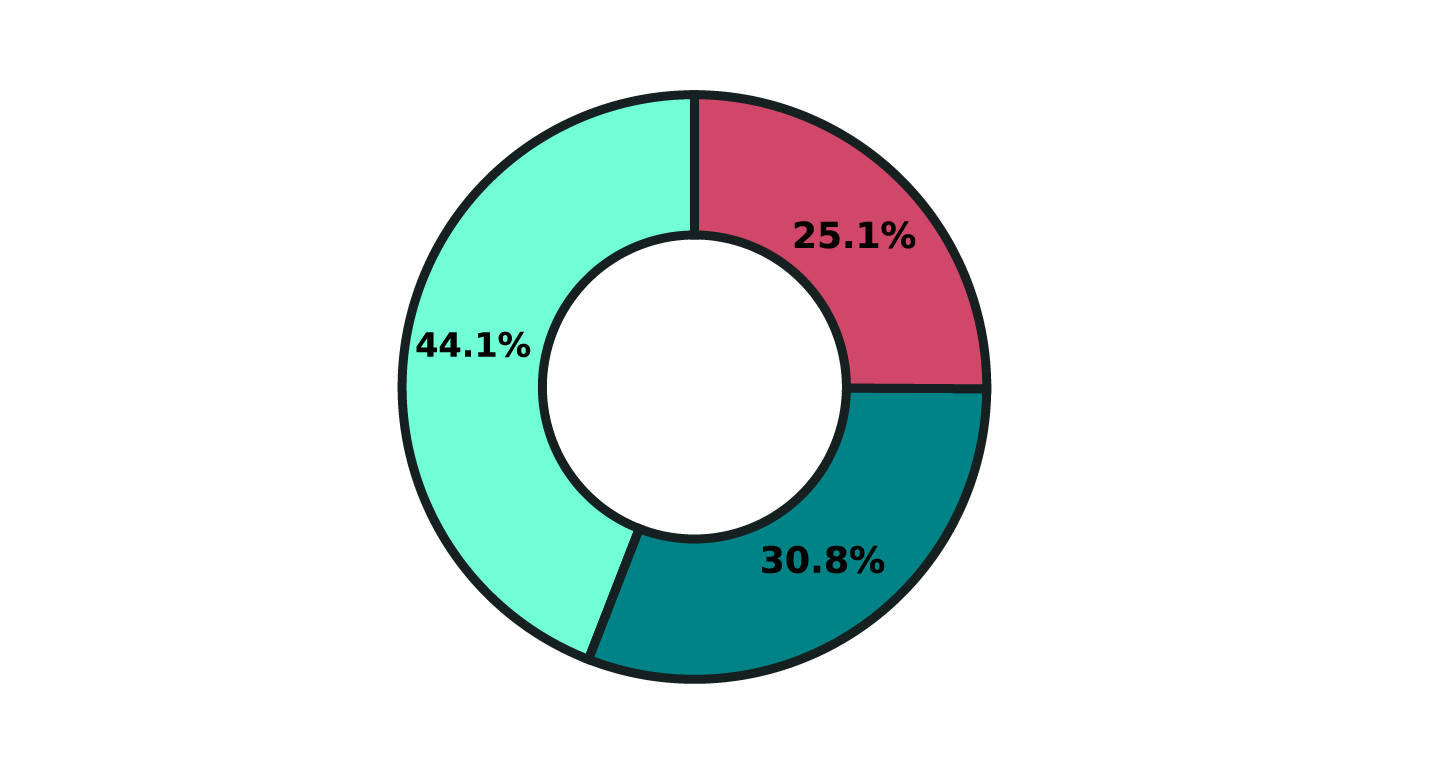
Company Size (n=295)
Use & Attribution
When referencing the survey findings, please use the full study title CloudBolt Industry Insights: The Kubernetes Automation "Trust Gap" in the first reference. Subsequent mentions can be shortened to "the survey" or "the study." Be sure to mention that CloudBolt Software commissioned the research in partnership with Gather. Always convey survey results objectively as reported. Interpretations of the data should be clearly distinguished from factual results.