Making Kubernetes Optimization Safer, Smarter, and Easier to Scale
Most teams don’t struggle to generate Kubernetes optimization recommendations. The harder part is acting on them in production without introducing risk, configuration drift, or more manual overhead than the savings justify.
That gets harder as environments grow. Optimization behavior ends up scattered across annotations and one-off exceptions. Some changes are safe to apply automatically; others carry a real risk of disruption. Modern delivery patterns add complexity. And HPA-managed workloads often get left alone entirely. Teams don’t want to touch scaling behavior they already trust.
We’re excited to announce a list of new capabilities that directly address those realities. Here’s what’s new.
Policy-based optimization configuration
We now support policy-based optimization configurations: reusable, cascading rules defined directly on the cluster.
apiVersion: optimize.stormforge.io/v1
kind: ClusterOptimizationConfiguration
metadata:
name: cluster-defaults
spec:
order: 10
rules:
- name: NAME
matchConditions: []
selector: {}
namespaceSelector: {}
settings: []
Platform teams can set org-wide defaults and guardrails. Application teams can tune behavior within the namespaces they own. Policies are evaluated in deterministic order, which makes the system easier to reason about when multiple rules apply to the same workload.
That matters because teams can answer practical questions without digging through layers of settings:
- Which rule is taking precedence here?
- Why did this workload get this recommendation?
- What changes if we update the default policy?
The result is a more scalable configuration model across teams and clusters that includes fine-grained targeting by workload type, labels, or namespace, with cascading rules that can be immediately validated on changes.
More resilient resource changes with in-place resizing
Recommendations only drive value if teams are comfortable acting on them. The hesitation usually isn’t about the recommendation itself. It’s about what happens when it’s applied. If a workload is restart-sensitive, changes stall. In many orgs, that’s enough to keep optimization permanently in review mode.
We’ve expanded in-place pod resizing support to make non-disruptive changes the default path wherever Kubernetes supports it. When in-place resizing isn’t an option, the platform now explicitly handles fallback behavior. This gives you better decision-making about when in-place resizing is appropriate, automatic rollback if application health degrades, and clearer handling of restarts when they’re unavoidable.
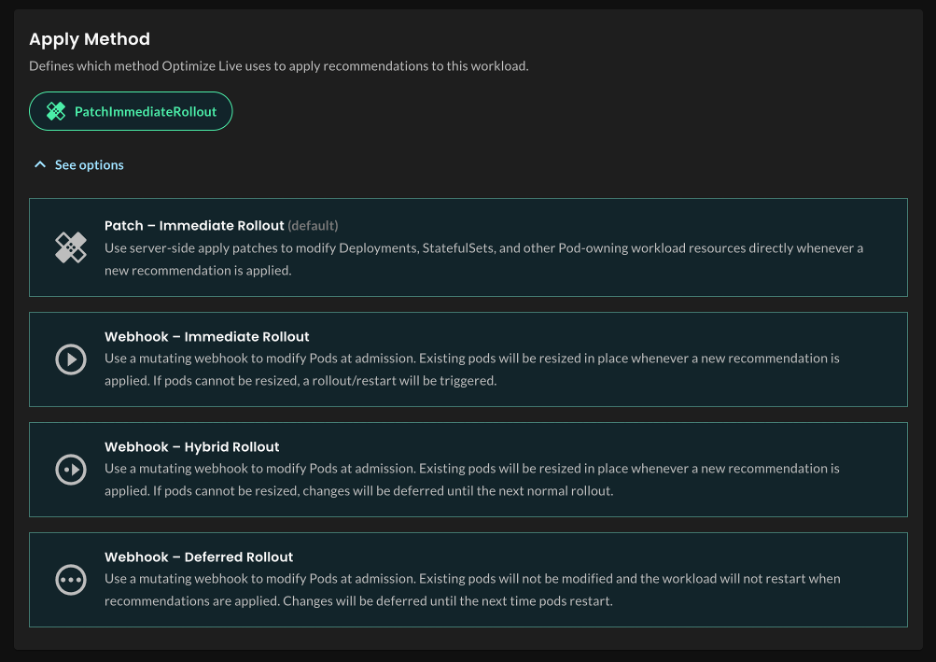
There are still tradeoffs, but they should be visible. Teams need to know when a change can happen in place, when a restart is unavoidable, and what happens if the workload reacts poorly. That’s what makes these changes operationally usable, not just technically possible.
Deployment-aware optimization
Blue/green releases, canary rollouts, progressive delivery, and warm-standby setups all create situations in which multiple workloads represent the same logical application but aren’t performing the same job at the same time. Some are serving production traffic. Others are in validation, on standby, or held back for failover.
If the optimization tool can’t tell the difference, the recommendations skew, or they slow down while waiting for enough data. We’ve added support for any type of grouped workload, such as canary workloads, blue/green deployments, or short-lived AI workloads that are all related. The system can recognize when related workloads belong to the same application context and intelligently determine how the usage should shape the recommendation.
HPA optimization without breaking scaling behavior
HPA-managed workloads remain one of the hardest areas to apply optimization with confidence. Teams often see obvious inefficiency but won’t touch anything that could alter the scaling behavior they rely on under real production load.
Our approach is to work with that constraint. This update enhances our patented ML method to recommend and apply resource changes while preserving a workload’s existing HPA behavior, including allocating additional resources when workloads are constrained, so optimization doesn’t push systems toward instability.
MCP server support in the CLI
With the rise of AI, engineers are increasingly driving investigations by asking tools questions rather than navigating UIs. When it comes to optimization, the questions are often straightforward: which workloads are consuming the most memory, where the gap is between current and recommended resources, and which services are overprovisioned versus constrained.
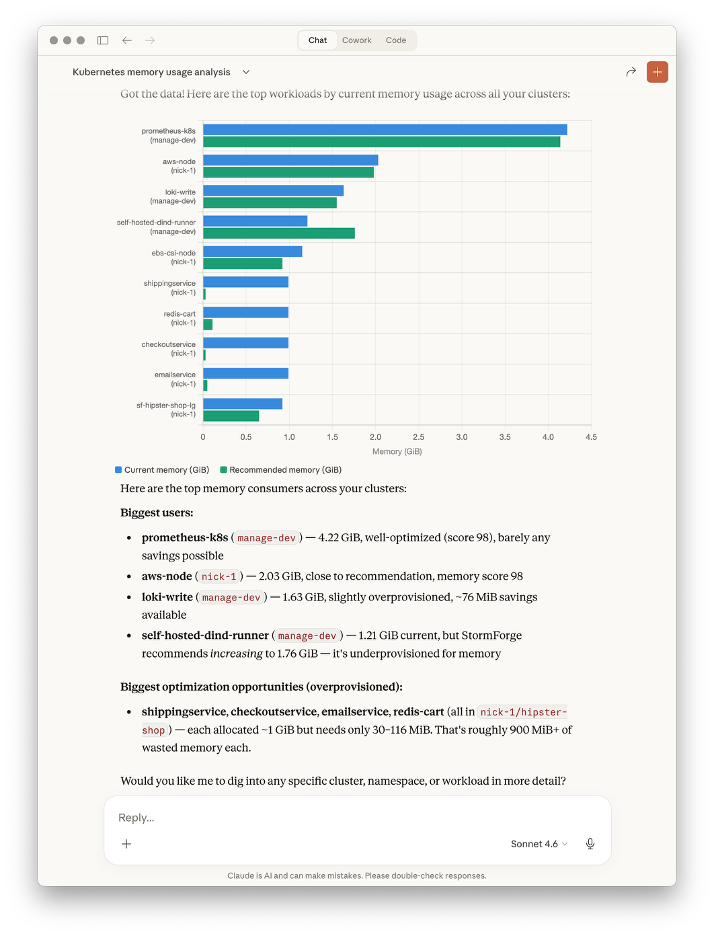
We now include MCP server support in the CLI, extending optimization insights to LLM interfaces such as Claude, ChatGPT, and Gemini. That shortens the path from question to action, especially during triage and planning, without requiring navigation through the CLI or UI first.
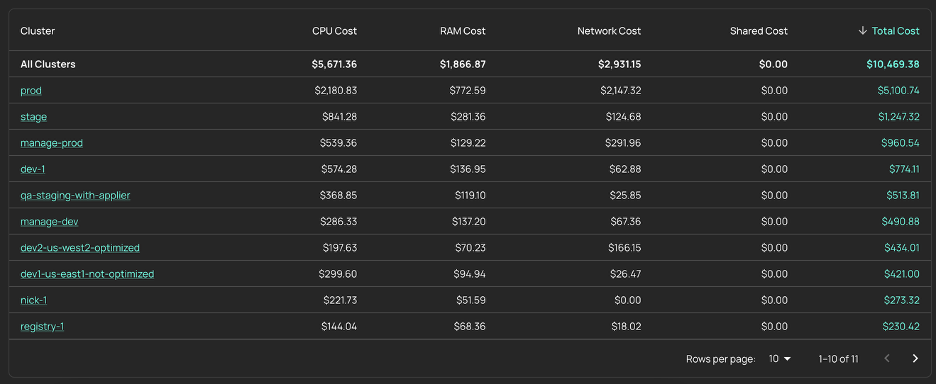
Kubernetes Cost Allocation is now GA
Kubernetes Cost Allocation is generally available, with additions that include: network cost support, exportable cost data, and expanded reporting in the UI. These additions matter most in environments where shared infrastructure, traffic patterns, and reporting needs make cost attribution harder than it looks from the cluster total alone. Better reporting and export help engineering, finance, and platform teams get to the same number.
What this means in practice
These changes all point in the same direction: making optimization easier to operate continuously in production. Some teams need a better configuration model because optimization logic is starting to sprawl. Some need a safer change application. Some need a path into HPA-managed workloads that doesn’t compromise scaling behavior. Others need better access to cost and recommendation data during day-to-day work.
The value isn’t in any single capability. It’s in reducing the friction that keeps optimization from becoming a continuous part of how teams run Kubernetes.
Start optimizing Kubernetes without disrupting how you scale
Start free trial


Related Blogs

When Karpenter isn’t enough: a real Kubernetes cost teardown
A high-volume payments platform runs hundreds of Kubernetes clusters and thousands of services, with a platform team responsible for the…

