Optimization Has a Trust Problem — and a Timing Problem
Most teams will tell you they’re doing continuous optimization. Their dashboards are full, their alerts are wired, and somewhere there’s a Jira ticket labeled “rightsizing.”
But when CloudBolt Chief Operating Officer Yasmin Rajabi took the stage at Converge, she shared numbers that told a different story.
“Ninety-two percent of leaders say they are mature in their optimization automation,” she cited from our Performance vs. perception: the FinOps execution gap report. “But when we looked at how often rightsizing, idle cleanup, and shutdown scheduling were a constant priority, it was only about 25 to 40 percent of the time.”
The gap between belief and behavior is the uncomfortable truth behind cloud optimization today. Most organizations aren’t falling short because they lack data or dashboards; they’re falling short because of two systemic gaps:
- A trust gap, where engineers hesitate to let automation act on their behalf.
- A timing gap, where optimization starts only after production is already in motion.
Until both close, “continuous optimization” remains more slogan than reality.
The Trust Problem
Engineers don’t distrust automation out of stubbornness. They distrust it because when something breaks, they’re the ones who get paged.
You can’t blame them either. A bad rightsizing recommendation can throttle a workload, break a release, or trigger a flood of restarts. That’s why so many teams default to manual review, even if it means the optimization backlog grows faster than the fixes.
Yasmin put it plainly: “Automation isn’t the blocker—trust is.”
Building that trust with engineers starts with guardrails, not guesses. The teams that get this right introduce automation in steps:
- Preview changes before they’re deployed.
- Set time windows (e.g. only execute at night, in dev first, etc.).
- Add thresholds such as not touching workloads unless utilization changes by 10% or more.
- Tune differently by environment (e.g. be more aggressive in non-prod, more conservative in production).
With those safeguards, engineers can start to let go without feeling like they’re losing control. Then, eventually, automation can become something they rely on rather than fear.
The Timing Problem
The second gap that gets in the way of true continuous optimization is subtler but just as damaging: optimization that starts too late.
For many teams, cost and performance tuning is still treated as a quarterly cleanup exercise or something to circle back to once everything is stable in production. Unfortunately, by then, drift and waste have already compounded.
Yasmin described it well: “If you’re waiting for production to be stable before you optimize, you’re already behind.”
True continuity means optimization starts before deployment, not after.
That’s where budget guardrails, tagging policies, and right-sizing defaults come in. When developers request new infrastructure, they should already see the projected cost and whether it fits the budget. If a large instance pushes them over, the platform should flag it or block it outright.
That shift—moving optimization earlier—changes everything. It prevents bad sizing decisions instead of remediating them. It turns “continuous optimization” from an endless backlog into an invisible safety net.
What Continuous Actually Looks Like
When trust and timing align, optimization stops being a manual process and starts becoming a property of the system itself.
Dashboards turn into signals. Signals trigger policies. And policies take action—safely, predictably, and continuously.
Yasmin shared one example of a customer that reduced its insight-to-action time from 30–90 days to literal minutes. By replacing ticket queues with policy-based automation, they cut through the lag that used to make “continuous” impossible.
Another organization, a large SaaS platform provider, used machine learning–based rightsizing to tune its Kubernetes workloads. Over time, it reduced cluster node counts from 26,000 to 5,000, cut costs by 71%, and improved uptime to 99.99%.
In both cases, the outcome wasn’t just savings—it was stability and trust. Engineers stopped firefighting and started building.
The Java Lesson
Java workloads are the perfect illustration of why trust and timing matter so much.
For years, teams have struggled with tuning Java applications in Kubernetes. Set the heap too small and you get OOM errors; set it too large and you waste memory. Traditional rightsizing tools can’t see what’s happening inside the JVM—heap usage, garbage collection, off-heap memory—so recommendations are blind guesses.
With StormForge Optimize Live, that opacity disappears. The system collects JVM-specific metrics and adjusts both the heap and the container limits together.
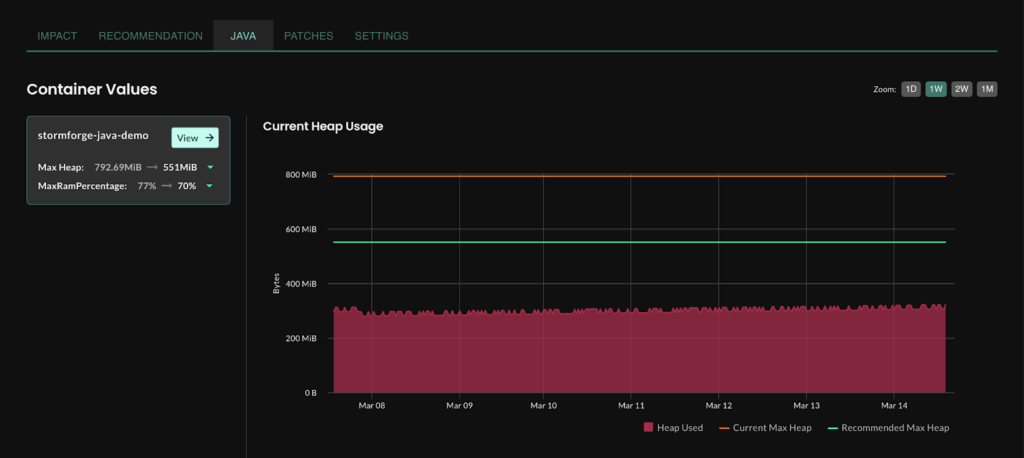
The result is JVM-aware optimization—tuning that developers can trust because it understands the workload it’s touching.
Once teams can see inside the JVM, they stop treating Java as the exception to automation and start letting optimization happen automatically.
Closing the Gaps
The Build-Manage-Optimize journey isn’t three steps—it’s one continuous loop.
- Build established how freedom and control can coexist.
- Manage confronted the myths holding teams back.
- Optimize exposes the last two barriers: trust and timing.
When those are fixed, optimization stops being an afterthought or a clean-up sprint. It just becomes part of the platform’s DNA.
Built for Kubernetes. Designed for What Comes Next.
Request a demo


Related Blogs

What actually happens when a workload OOMs in production
The pager goes off at 2:47 AM. CrashLoopBackOff on a payment service. The on-call rolls over, opens a laptop, runs…

