Beyond ClickOps: A Better Model for Self-Service at Scale
Self-service in cloud environments has always carried a certain promise: faster delivery, less friction, and fewer bottlenecks between developers and the infrastructure they need. But despite years of effort—and a long trail of portals, request forms, and automation scripts—most organizations still haven’t cracked the model.
What’s surfaced instead is a structural tension: the more flexibility teams introduce, the more risk they take on. The more they tighten control, the more they become a blocker.
Somewhere between “do everything manually” and “let everyone do whatever they want,” most platform and infrastructure teams now find themselves trying to answer a harder question: How do we enable safe, scalable self-service without losing control of cost, compliance, or complexity?
This was the central topic in the “Build” session at Converge 2025 where Chief Customer Officer Shawn Petty, Director of Global Pre-Sales Engineering Mike Bombard, and Co-Founder and VP of Customer Support & Product Architect Auggy Da Rocha drew on customer examples, operational frameworks, and hard-earned lessons from the field to reframe what successful self-service actually looks like in modern cloud environments.
Where Self-Service Breaks Down: The Limits of One-Size-Fits-All
If self-service promised to give developers faster, easier access to infrastructure, the reality has been messy. Teams either introduce too much control and become bottlenecks—or open the floodgates and lose governance entirely. Most organizations still treat this as a tradeoff.
But at scale, neither extreme holds up. “We kind of get caught in this false all-or-nothing binary around self-service,” said Shawn. “Either you lock everything down and become a bottleneck, or you open the floodgates and lose control.”
“We kind of get caught in this false all-or-nothing binary around self-service. Either you lock everything down and become a bottleneck, or you open the floodgates and lose control.”

This isn’t just a philosophical tension; it’s an operational one. In tightly controlled environments, a basic provisioning request might take weeks to fulfill. Developers, under pressure to move, start working around the system: setting up their own cloud accounts, circumventing tagging standards, and deploying infrastructure without guardrails.
In looser environments, the risk flips. Standards get ignored. Naming conventions drift. IP collisions happen. Teams end up with hundreds of unmanaged cloud artifacts and no unified way to track them. “Even minor misconfigurations—like a fat-fingered IP range—can knock a system offline,” Mike said. “And those mistakes happen more often when you’ve created a free-for-all provisioning culture.”
The real issue is that these teams are applying a single model to all workloads when what they actually need is a spectrum of models based on the workload’s requirements.
Some workloads—like regulated app backends—require rigid controls. Others—like internal dev environments—require near-total flexibility. Without a framework to differentiate between them, self-service ends up being either overly constrained or dangerously permissive.
To fix this, organizations need to move beyond the binary and start applying control and flexibility where they actually belong based on the nature of the workload, the environment, and the business risk.
That’s where blueprint-driven automation starts to matter.
Blueprint-Driven Automation: Consistency Without Bottlenecks
One of the clearest models to emerge from the Build session was the idea of blueprint-driven self-service.

Since our customer event was at the Porsche Experience Center in Atlanta, it’s only fitting that Auggy used a Porsche analogy. In Porsche’s production line, every car starts from a standard, engineered foundation: the chassis, engine, safety systems, and core electronics are all fixed. But buyers still expect to customize features like seatbelt colors, wheel options, trim packages, and interior styling. “The 911 that rolls off the line is the same across every model,” he said. “But none of us want to drive the exact same car. That’s where controlled customization comes in.”
Applied to cloud delivery, the base blueprint is the governed, reusable automation that defines the secure, compliant way to deliver a workload—a VM, a database, a Kubernetes namespace, or an entire environment. But the blueprint is designed to be extended—parameters can be exposed for dev teams to choose regions, instance sizes, or storage tiers depending on their needs.
This is how teams like Nationwide, Leidos, and others have scaled self-service without splintering into snowflake environments. But there’s nuance here. Too much flexibility inside the blueprint, and you risk losing standardization. Too little, and platform teams are forced to create dozens (or hundreds) of near-duplicate blueprints just to support common variations.
“You don’t want to shift from managing workloads to managing a blueprint for every possible flavor of that workload,” Auggy warned. “You have to leave room for flexibility without turning it into sprawl.”
This is why the strongest blueprint models rely on modular design and meaningful user inputs, not endless form fields. Devs should answer a few key questions (What kind of environment? Any compliance requirements? High availability needed?), and the blueprint logic handles the rest.
The result isn’t just speed. It’s repeatable infrastructure delivery that supports auditability, cost predictability, and developer experience all at once.
Real-World Patterns: Matching Delivery Models to Workload Realities
One of the most overlooked challenges in cloud infrastructure delivery is the assumption that every workload should be treated the same. In reality, the requirements for delivering a PCI-regulated application backend are radically different from those of a research prototype or a proof-of-concept dev environment.
During the Build session, Mike and Auggy laid out a framework many mature platform teams are now using: Map your workloads along a spectrum of control and flexibility, then build delivery models around those patterns.
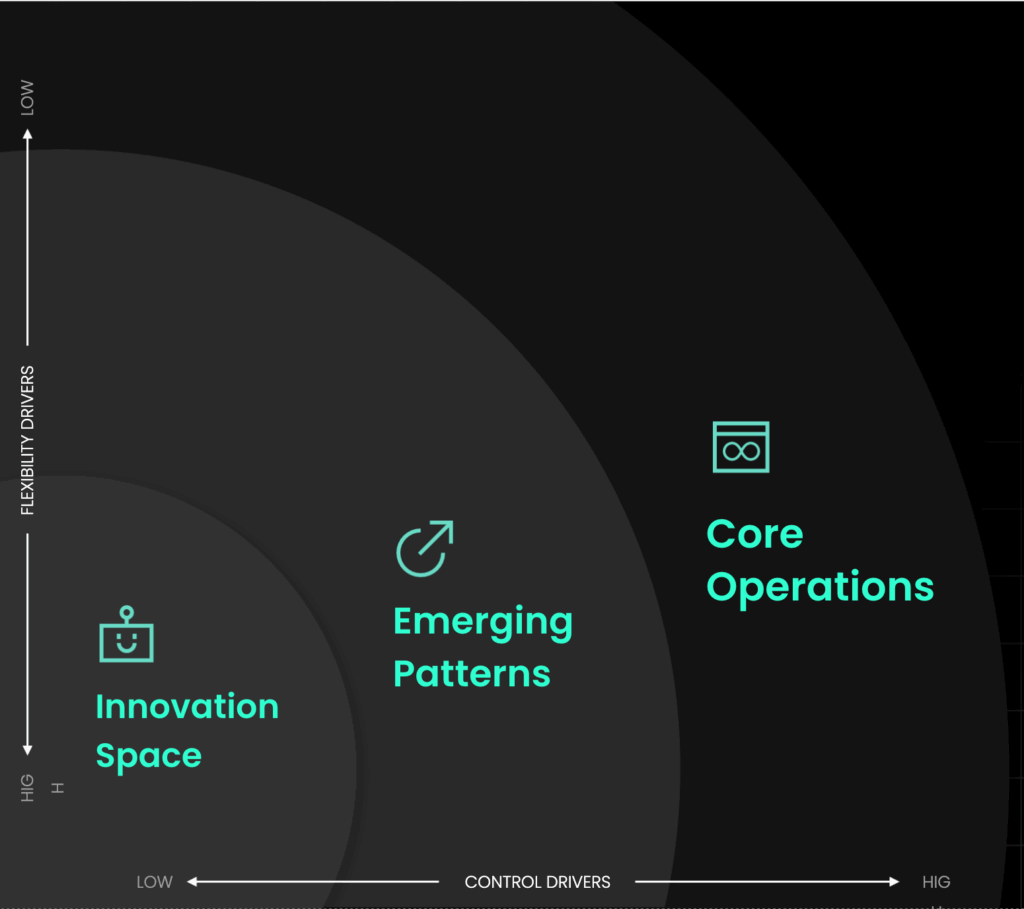
At one end of the spectrum are what Mike called core operations—workloads that have to be provisioned the same way every time. These include environments governed by compliance frameworks like PCI, HIPAA, or FedRAMP, where even minor deviations can trigger audit failures or security vulnerabilities. In these cases, control is non-negotiable: predefined templates, pre-approved configurations, and strict deployment standards are required. “You have no margin for error when it comes to compliance,” he said. “The platform should make sure those environments are provisioned correctly every single time—no exceptions.”
In the middle of the spectrum, you have repeatable workloads with slight variations—like point-of-sale (POS) deployments across retail stores. For some locations, the baseline environment is sufficient. For others—high-traffic stores or locations with specialized hardware—additional resources or custom configurations may be needed. These situations benefit from blueprint-driven automation with optional parameters that allow scaling or minor adjustments without altering the core architecture.
At the far end of the spectrum are innovation or R&D use cases—highly dynamic, often experimental environments where speed and flexibility matter more than standardization. Trying to enforce strict provisioning patterns here doesn’t just frustrate developers, it actively slows the business down. “I was just talking to a customer last week,” Auggy said. “Their developers are as cloud-native as it gets, and they’re allowed to go to AWS directly. But when they go through the internal platform, security and compliance is handled for them. It’s not a mandate—it’s a better experience.”
This spectrum-based approach acknowledges that not all infrastructure needs the same guardrails, and that the most effective platform teams apply controls where they matter and get out of the way where they don’t.
What Good Looks Like
In organizations that have closed the self-service gap, a few patterns consistently show up—not just in tooling, but in mindset and process:
1. Self-service is designed around patterns, not exceptions.
Instead of reacting to every one-off request with a new ticket or custom script, platform teams define reusable patterns for common workloads. They then continuously refine those patterns over time.
2. Governance is built in, not bolted on.
Security policies, tagging standards, budget controls, and approvals are embedded into the provisioning logic. That way developers don’t have to think about them, and ops teams don’t have to chase them down.
3. Flexibility is intentional.
Teams expose only the variables that matter, and only where it’s safe to do so. The result is self-service that feels permissive to the user but is actually tightly controlled behind the scenes.
4. Devs use the platform because it’s better, not because it’s required.
When you provide an internal experience that makes life easier, reduces risk, and delivers faster results, developers will choose it. Not out of obligation, but because it works.
Final Thought
Cloud complexity isn’t going away. If anything, it’s increasing—spanning more teams, more environments, more constraints. But the answer isn’t to pull everything behind a gate and call it governance. Neither is it letting go of the wheel and hoping for the best.
The answer is a platform model that respects the needs of the business and the realities of engineering by combining blueprint-driven automation, intelligent governance, and workload-aware flexibility into a model that actually works at scale.
Build Once, Govern Everywhere
Book a demo

Related Blogs

What actually happens when a workload OOMs in production
The pager goes off at 2:47 AM. CrashLoopBackOff on a payment service. The on-call rolls over, opens a laptop, runs…

