The COGS case for Kubernetes rightsizing






Why StormForge?

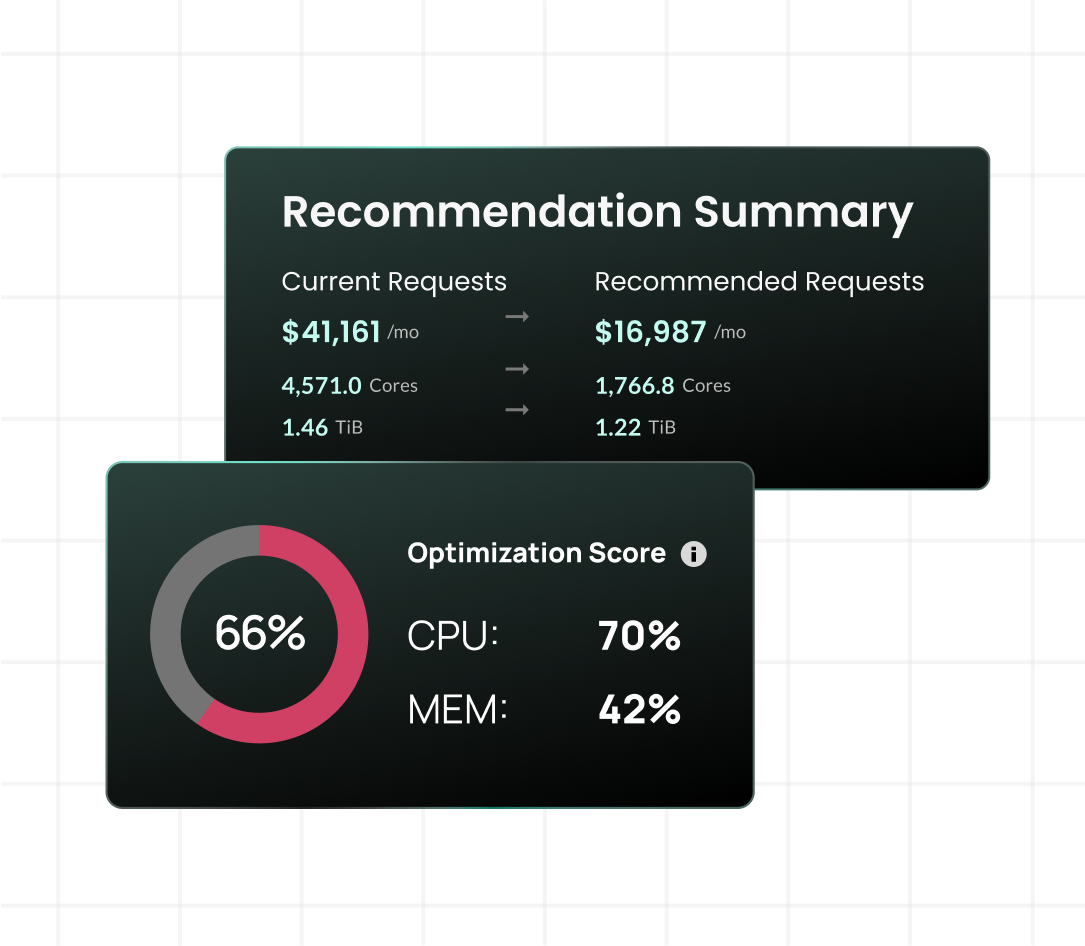
Up to 80% reduction in K8s infrastructure costs

Direct cost of goods sold (COGS) impact on the P&L

30-day guarantee
THE COGS PROBLEM
Two problems, one root cause
For any company delivering software as a service, Kubernetes compute is cost of goods sold. Overprovisioned resource requests mean you’re paying for 2–5x what your workloads actually consume. That gap is pure gross margin waste.
The financial problem
- Infrastructure costs scale with requested resources, not actual usage
- Every overprovisioned vCPU is gross margin left on the table
- SaaS businesses depend on gross margin; COGS reduction flows directly to the metric boards and investors care about
- At scale, the waste compounds: overprovisioned pods force the cluster autoscaler to provision larger or more nodes than necessary
The engineering problem
- Developers overprovision for rational reasons: they’re measured on uptime, not efficiency
- Nobody gets fired for overprovisioning. People have been fired for causing outages.
- Manual tuning breaks down at scale: nearly 70% of teams say it becomes unsustainable past 250 changes per day
- The incentives don’t align between the teams setting requests and the teams responsible for platform efficiency
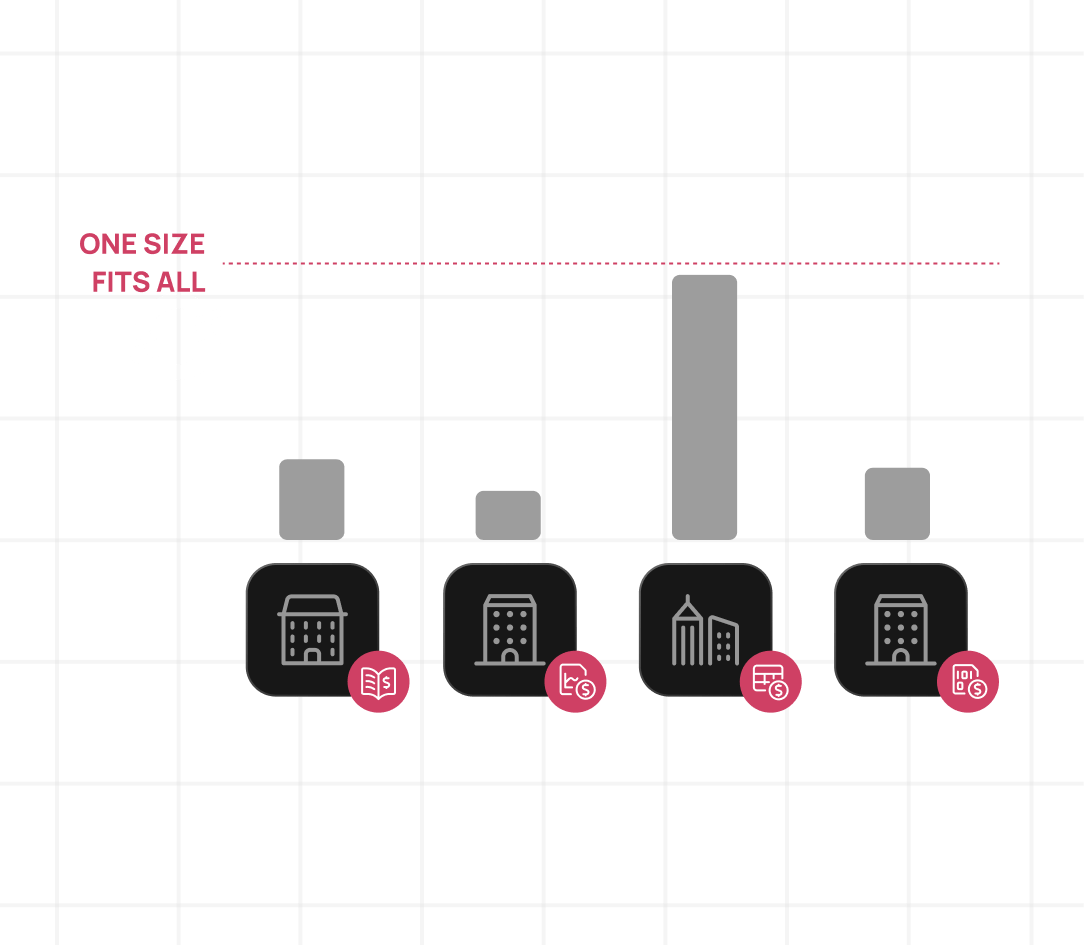
Why one-size-fits-all doesn’t work
- Every customer is a snowflake – same application, but traffic patterns, data volumes, and feature usage all vary across tenants
- One-size-fits-all doesn’t work – a single resource setting can’t be right for every customer running the same workload
- The alternative is chronic overprovisioning – most teams set resources to cover the worst case for every customer, which is expensive COGS carried across your entire base
- Per-workload ML solves this – StormForge builds a dedicated model for each workload, capturing each customer’s specific resource behavior rather than applying a blanket recommendation
How StormForge closes the COGS gap

Observe
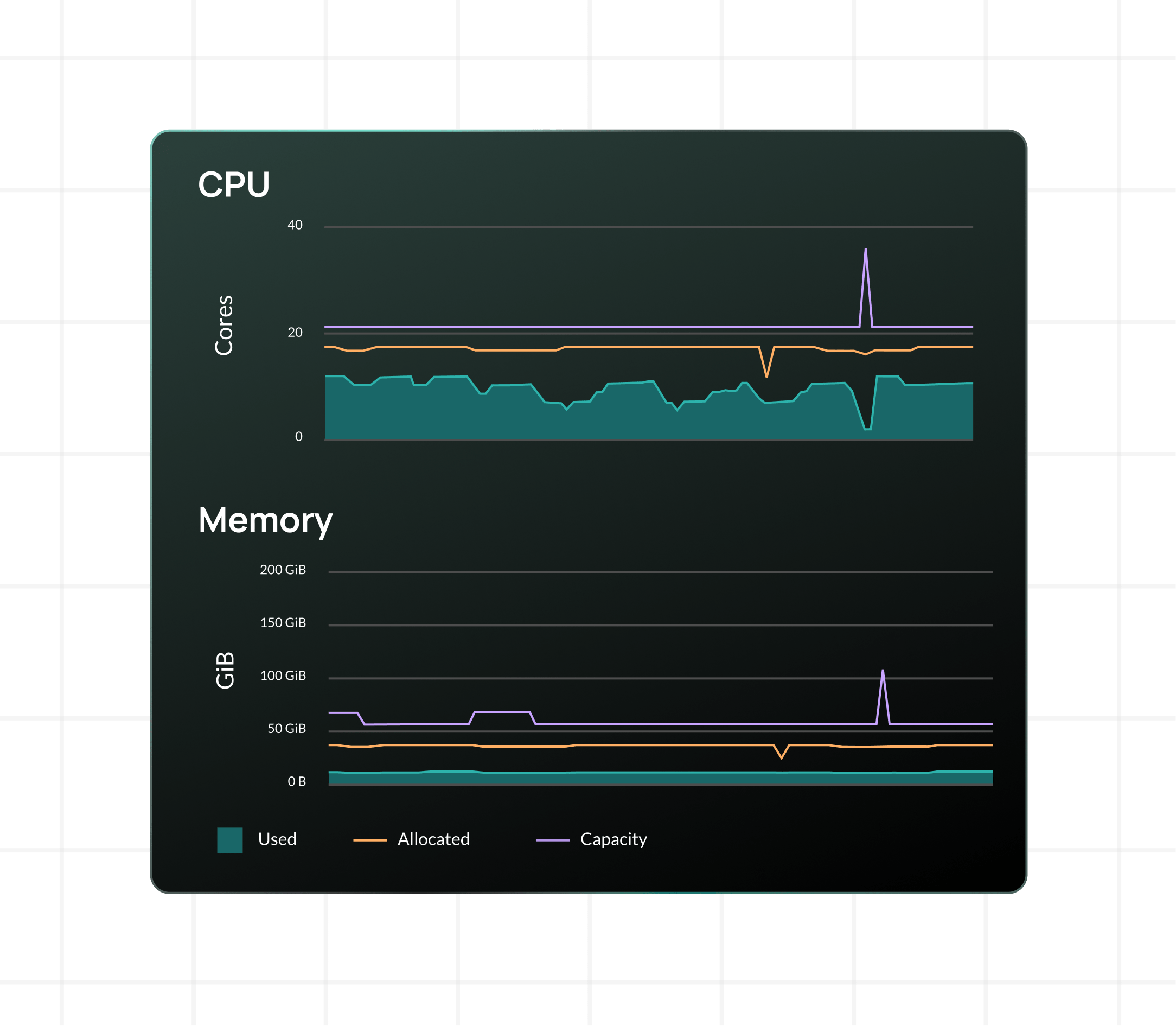
Continuously collects CPU, memory, and scaling data from live workloads across your entire estate.

Analyze
Per-workload ML models trained on 28+ days of data determine optimal resource settings without risking performance. Captures weekly patterns, daily cycles, and burst behavior unique to each workload.

Recommend surfaces
Rightsizing changes with projected savings mapped to actual COGS impact. JVM heap optimization for Java workloads. OOM protection built in.

Apply
Automatically implements changes with safety guardrails: automatic rollback, drift reconciliation, and patented bi-dimensional autoscaling that preserves HPA scaling behavior.
Why reliability is the bridge to the CFO
The reliability angle isn’t separate from the cost story — it unlocks it. Dev teams overprovision because they fear outages. That buffer isn’t protecting reliability. It’s masking it. StormForge improves both simultaneously.
- CFOs – Every vCPU you don’t need is gross margin left on the table. This is a P&L play, not an IT project.
- Platform engineers – Fewer OOM kills, less throttling, stable HPA behavior — within the reliability boundaries your team is already held to.
- Engineering leaders – Reduce cloud spend without slowing down development. Teams control the pace of automation.
- FinOps teams – Continuous and automatic optimization with audit trails and cost allocation at the namespace and workload level.

How Acquia did it
Acquia saw a 65% reduction in web node infrastructure, 99.99% availability maintained, and migrated from 26,000 EC2 nodes to Kubernetes.
For on-prem or OpenShift users
Not every COGS story involves a cloud bill
- When infrastructure is on-prem, the story shifts to cost avoidance. Reclaim overprovisioned capacity and delay hardware purchases by 12-18 months
- For OpenShift environments, reducing vCPU count directly reduces Red Hat ELA licensing costs (OpenShift is licensed per vCPU)
Your Kubernetes COGS, optimized
Get started for free

Ready to learn more?

The Kubernetes Automation Trust Gap No One Talks About
CloudBolt Research Report — March 2026 The Kubernetes Automation Trust Gap No One Talks About The selective distrust of autonomous Kubernetes rightsizing, and how to overcome it. 321 Respondents| Enterprise Orgs (1,000+)| 100% Kubernetes Practitioners 00Executive summary 01Automation is doctrine 02The moment trust breaks 03High belief, low delegation to automation 04This isn’t irrational 05Scale vs. […]
Bill-Accurate Kubernetes Cost Allocation, Now Built Into CloudBolt
CloudBolt is introducing granular Kubernetes cost allocation directly within the platform, now available in private preview. This new capability delivers bill-level accuracy down to the container, intelligently allocates shared costs, and integrates natively with enterprise chargeback. If you’d rather see it than read about it, start with a quick walkthrough of the experience: Here’s what […]
How Acquia cut web node infrastructure by 65% with continuous Kubernetes rightsizing
Acquia modernized a platform that previously ran on roughly 26,000 EC2 nodes by moving to Kubernetes. The goal wasn’t just containerization—it was elastic scaling for traffic spikes without relying on fixed “small/medium/large” sizing. Results at a glance 65% reduction in web node footprint 99.99% availability delivered consistently 26,000 EC2 nodes as the legacy baseline modernized […]
FAQs
-
What is COGS in the context of Kubernetes?
For any company delivering software as a service, Kubernetes infrastructure costs (compute, memory, storage, networking) sit on the cost of goods sold line. These are not IT overhead costs. They are the direct cost of delivering your product to customers. When workloads are overprovisioned, COGS increases without a corresponding increase in revenue, which compresses gross margins.
-
How does Kubernetes overprovisioning affect gross margins?
Most Kubernetes environments are paying for 2-5x what workloads actually consume. Developers set resource requests conservatively to avoid outages, which is rational behavior. But at scale, that conservatism translates directly into excess infrastructure costs on the COGS line. Reducing overprovisioning by even 30-40% can meaningfully improve gross margins without any change to the product or go-to-market.
-
Why is rightsizing harder for SaaS companies?
Because every customer is a snowflake. SaaS vendors run the same application for every customer, but each customer’s resource profile is different. Traffic patterns, data volumes, feature usage, and integrations all vary. A one-size-fits-all approach to resource settings doesn’t work when every workload has a unique usage pattern. This is why per-workload ML matters: StormForge builds a dedicated model for each workload rather than applying a single set of recommendations across the board.
-
How does StormForge reduce Kubernetes COGS?
StormForge uses per-workload ML models trained on 28+ days of usage data to generate CPU and memory recommendations that reflect actual workload behavior. Recommendations are applied automatically with safety guardrails including automatic rollback, OOM protection, and drift reconciliation. The result is lower resource requests per workload, which means fewer nodes needed, which means lower infrastructure costs on the COGS line.
-
Does reducing resource requests risk reliability or performance?
No. StormForge is designed to improve reliability alongside cost reduction. Memory recommendations include OOM protection. HPA scaling behavior is preserved through patented bi-dimensional autoscaling that adjusts requests and HPA targets as a coupled pair. If application health degrades after a change, the system rolls back automatically. The goal is to eliminate waste without touching the reliability boundaries your team is accountable to.
-
What about on-prem or OpenShift environments where there’s no cloud bill?
When there’s no direct cloud bill to reduce, the COGS story shifts to cost avoidance. Rightsizing workloads frees overprovisioned capacity, delaying hardware purchases by 12-18 months. For OpenShift environments, reducing vCPU count directly reduces Red Hat ELA licensing costs (OpenShift is licensed per vCPU). The frame is: we extend your existing hardware budget runway.
-
How do I get started?
StormForge is available as a free trial on AWS Marketplace with pay-as-you-go pricing. Installation takes under 10 minutes. Recommendations appear within about two minutes. Start in recommendation-only mode to review before enabling automation. 80% savings, no compromise on reliability, 30 days, guaranteed.