We would all like our IT infrastructure to always run smoothly and be fault-tolerant, secure, and modern without needing intervention. The reality, however, is that no matter what the infrastructure looks like or where it runs, it requires constant operational activities to maintain peak performance.
Some organizations have strived to reduce their data center operational tasks, opting for a public-cloud-based infrastructure and leaving the days of swapping failed power supplies and planning for network switch port allocation behind. Others have opted to grow their private cloud presences to meet specific privacy requirements or to focus on the most efficient infrastructure delivery models for their businesses.
Whatever approach is taken, nearly all organizations must deal with some level of operational responsibilities in maintaining their desired levels of availability and the appropriate security posture. And while operations are rarely the most interesting aspect of IT, finding ways to enable them effectively can be challenging.
This article recommends the best practices for running smooth operations when it comes to IT infrastructure.
Key elements of infrastructure operations
The table below lists the most important recommendations and considerations for infrastructure operations.
| Element | Description |
|---|---|
| Eliminating silos | Historically, complex and ineffective management interfaces for IT infrastructure have resulted in siloed operations teams. Currently, available tooling allows for more direct and efficient interactions between operations teams. |
| Workload classification | Different types of workloads require different operational efforts and methods. The more classical infrastructure with highly customized deployments that are created with little to no automation is difficult to rebuild and requires in-place updates and time-intensive troubleshooting when problems arise. In contrast, more modern systems that are highly automated and oftentimes are partially stateless can be viewed as easily replaced disposable components. Clearly understanding where your application infrastructure lies between these two models brings valuable input into future operations and modernization planning. |
| Reliability engineering practices | The core site reliability engineering (SRE) principles encompass the modern approach to infrastructure operations. These principles, while typically more often applicable in a fast-paced software development setup, have a lot of advantages in operating even core infrastructure components. |
| Repeatable workload provisioning | Automated workload provisioning and de-provisioning is the key to consistent outcomes with no manual interactions for both physical hardware and customer workloads. |
| Daily support activities | Even in environments not based on infrastructure as code, classical activities like server patching, vulnerability management, and network equipment configuration can be organized to reduce manual operational efforts. |
| Common management layer | A common management methodology reduces overhead and leads to fewer knowledge islands. With hardware and software vendors offering programmatic access to their products, a higher level of integration and reduced manual effort can be achieved. |
Watch how orchestration brings order to IT chaos.
Eliminating silos
Classical infrastructure operations teams usually consist of a first-level operational team taking care of server and network incidents and outages, plus specialized teams able to resolve more complex issues related to operating systems, virtualization platforms, networking, or storage infrastructure.
This setup made sense: You could not expect a Windows engineer to troubleshoot a Fibre Channel storage area network because these engineers’ capabilities were completely different. However, the lack of common observability tooling and application-level monitoring contributed to these different specialties becoming closed up in their own knowledge domains. This could lead to finger-pointing, especially in the case of severe incidents.
Recent years have seen advancements in management tools, broad adoption of REST API management interfaces, and software-defined technologies in all areas—even at the physical server level. This has resulted in the siloed specialist model losing much of its relevance.
Infrastructure component vendors have introduced more convenient and connected management capabilities. The public cloud space has exploded with state-of-the-art infrastructure management capabilities, and third-party vendors have also introduced tools that can combine, correlate, and control different parts of the infrastructure.
Offering unified management, modern platforms like CloudBolt break down silos and foster collaboration across the entire infrastructure stack. With centralized security, compliance, provisioning, and FinOps control under one roof, CloudBolt eliminates the need for disparate tools and manual handoffs, empowering teams to:
- Respond to incidents faster with real-time visibility and automated workflows.
- Reduce duplicated efforts by streamlining provisioning and compliance tasks.
- Break down departmental barriers through role-based access controls and collaborative dashboards.
- Make data-driven decisions with comprehensive FinOps reporting and cost optimization tools.
Recommended practices
- Start building cross-functional teams. This should not mean making network engineers learn the ins and outs of Windows Server debugging, for example. However, just like the slogan that “everyone is part of the security team,” everyone should also be part of the automation and integration team.
- If the engineering and operations teams are completely separate, start introducing them to one another. Having the first responders as customers will allow the engineering teams to look at the problems from a different angle and come up with more comprehensive solutions.
- Use observability tooling such as CloudBolt for a unified view of the infrastructure, not just parts of it.
Workload classification
While it is always tempting to “just move everything to the cloud” to reduce operational efforts, that is not always feasible from a cost perspective and may not even be possible at all in some cases. The types of workloads the organization has can have a significant effect on what operational activities it needs to undertake. The way that the team treats its infrastructure can be better understood using the “pets and cattle” analogy.
If an organization is running a large number of classical applications hosted on physical servers or virtual machines, they might be treating them as “pets.” This means that they care for each as a crucial part of the infrastructure, spend lots of time troubleshooting them when they are not operating correctly, do in-place updates and treat their decommissioning as a significant project. If that’s the case, there’s a limited number of operational improvements that can be achieved without at least re-platforming the application.
In contrast, when an organization adopts viewing its infrastructure as disposable and rebuildable, the servers are treated like “cattle.” If there is an ability to spin up a new server or container in seconds or minutes, there’s no need to spend hours troubleshooting it. This brings the potential for simplified operations, increased resilience, and automatic healing.
With tens or even hundreds of business applications, there’s a good chance that some of the applications might be more modern and some less. Clearly understanding the infrastructure of each application can substantially help in evaluating which application is being operated efficiently and which parts would benefit from improvements the most. This can often be the basis for prioritizing migration and modernization projects.
Even with workloads already running in seemingly modern public cloud environments or a hybrid environment, it is important to classify workloads as a periodic activity to reevaluate previous decisions through the lens of the changing landscape. The classical Cloud Adoption Framework can be utilized in this continuous cycle even if no public cloud provider is in the picture:
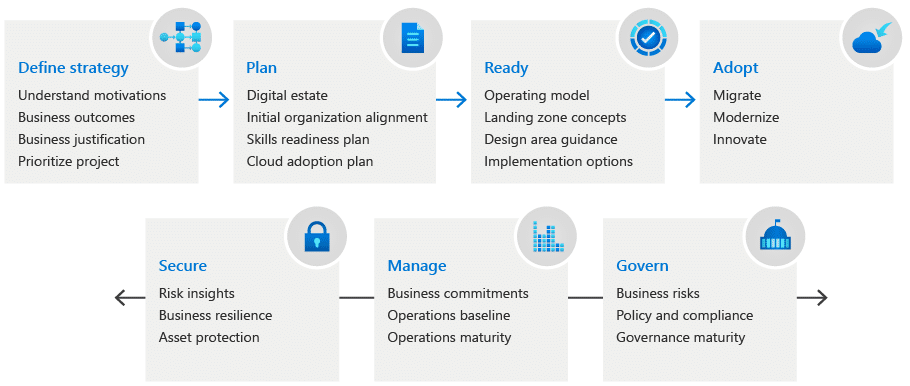
In a non-uniform enterprise cloud environment that might include resources in multiple local data centers and/or with many cloud providers, it is essential to have the ability to see an overview of the entirety of the infrastructure landscape. Doing so will leave no blind spots while identifying truly needed resources and the true cost of certain parts of the infrastructure. It will also indicate a modernization path and show the potential impact on expenses.
See how CloudBolt connects tools, teams, and clouds into one governed workflow.
Recommended practices
- Ensure that your assets are well-defined, regardless of the infrastructure type or the tools being used—an ITSM system, tagging mechanisms in your virtualization platform, or the public cloud. Having a clear understanding of which business service a particular asset belongs to, what environment it corresponds to, and who the owner is are key items of information when doing maintenance or planning modernization.
- Identify potential candidates for modernization. Group your applications and their assets based on criticality and evaluate their ability to be migrated to infrastructure solutions requiring less maintenance (stateless containers, functions, or at least re-deployable virtual servers).
- Consider TCO when creating the business case for migrating or modernizing an application. Operational expenses are often a lead contributor to the cost of an application’s infrastructure. While the cost of migrating a project might seem high at the beginning, the migration might save more over a longer period.
Reliability engineering practices
Site reliability engineering (SRE) is currently the best-established set of standards and principles for building and operating infrastructure. Introduced by Google, SRE started gaining traction about half a decade ago among agile organizations building software and taking care of large and complex infrastructures. However, that does not mean that other types of organizations cannot benefit from adopting these practices or that they need to start instantly restructuring their IT departments.
SRE is not a prescriptive framework but rather a set of values that can be applied by any organization doing infrastructure operations:
- Embracing risk: Despite how it might sound, this principle is not about being a cowboy in the data center and starting to experiment on production servers. It is about understanding that there’s always a way you can chase that additional “nine” in your system’s availability numbers. However, the more you try to push beyond a certain threshold, the more expensive it becomes. Understanding when reliability is good enough is key. And if it is not where it should be and the classical methods are not working, proposing and building a different solution should be encouraged.
- Service-level objectives: While 100% uptime might be the holy grail of reliability engineering, it might not mean 100% user satisfaction. If we are focused on metrics that do not show the full picture of what the user is experiencing, we will not be able to improve our systems most effectively.
- Eliminating toil: This is the most essential part of the SRE philosophy in any IT operations organization. Toil is repetitive work, which, while essential, does not require a lot of skill and mostly eats up valuable time. Elimination of such activities is the key to increased departmental efficiency.
- Monitoring: The main purpose of monitoring your infrastructure is to reliably track its status and provide a full picture of what is happening with business-critical applications.
- Release engineering: While typically less familiar to operations-focused teams, release engineering ensures that infrastructure changes are treated like software code changes. This is typically adopted as the teams mature and operate on highly automated platforms that require constant adaptation and changes.
- Automation: Automation is key to toil elimination and the biggest contributor to increased operational efficiency. Even if just part of the team is proficient at scripting, their work can be amplified and utilized by less senior colleagues with the help of automation platforms like CloudBolt.
- Simplicity: If there is a particular problem, the solution must resolve that problem specifically, not all the problems that the company might have. Simple solutions lead to quick reaction times and easy-to-understand implementations.
Initially, the SRE practices may sound like they are not well suited to a traditional ITIL-driven operations department. However, this is just the surface view. Each activity can still follow the internal incident, change, and problem management procedures, with automated entries in your IT service management platform and manual approval gates where they are needed. If anything, the automation-driven increase in implementation speed might help the organization better understand where current manual operations could be replaced by automatic approvals.
Depending on your current infrastructure and operational activities, the paths to adopt these practices might also be different. It is easy to propose the adoption of infrastructure as code and start modernizing operations immediately. However, the reality is that changing current practices and upskilling an entire team or even a department in a short time is not realistic. In these situations, tooling that is understandable to the current engineering team allows the embracing of modern ways of working and does not pose a risk of vendor lock-in can be a great solution when modernizing your infrastructure and how it is operated.
Watch how CloudBolt transforms provisioning from a week-long process into minutes — without replacing your existing tools.
Recommended practices
- Set the right service-level objectives (SLOs) that are not engineer-focused but rather user-focused.
- Set time aside for the operational teams to work on service improvements that bring more value in the longer term.
- Look at both free and open source and commercial solutions that offer relevant solutions for the challenges you face.
- The monitoring discipline is not only about the health and performance of the infrastructure. For infrastructures running in highly scalable public cloud environments, the usual monitoring should be supplemented by cost monitoring / financial reporting, cloud spend budget policies, and chargeback mechanisms.
Repeatable workload provisioning
The current infrastructure landscape is very much geared towards automation. While the public cloud has brought the convenience of workload provisioning at scale, the automation capabilities are available outside of the public cloud as well. From standalone bare metal servers (that now include management utilities) and hardware-level configuration APIs to hypervisors and the whole virtualization platform, all layers needed to deploy your workload can be automated end-to-end. This applies not only to standalone servers but to entire compute clusters, networking components, and storage arrays in today’s software-defined data center.
Regardless of where the workloads are being deployed, if an organization requires new workloads at least every week, the provisioning process should be automated. Automation not only speeds up the provisioning time and saves on provisioning effort but also eliminates the potential for human error from the equation.
An added benefit to being able to provision infrastructure and applications easily is the ability to start looking at your infrastructure as more disposable and, in case of issues, see redeployment as a viable alternative to long troubleshooting hours.
If your primary workloads are physical or virtual machines, the building of golden images and adoption of declarative configuration management can be the core of consistent workload provisioning. A golden image is a reference template of your server, which might include the latest security updates, required applications, and settings and can be deployed on your infrastructure. As all (or at least most) of the configuration is already done, the provisioning is much faster than configuring some settings afterward.
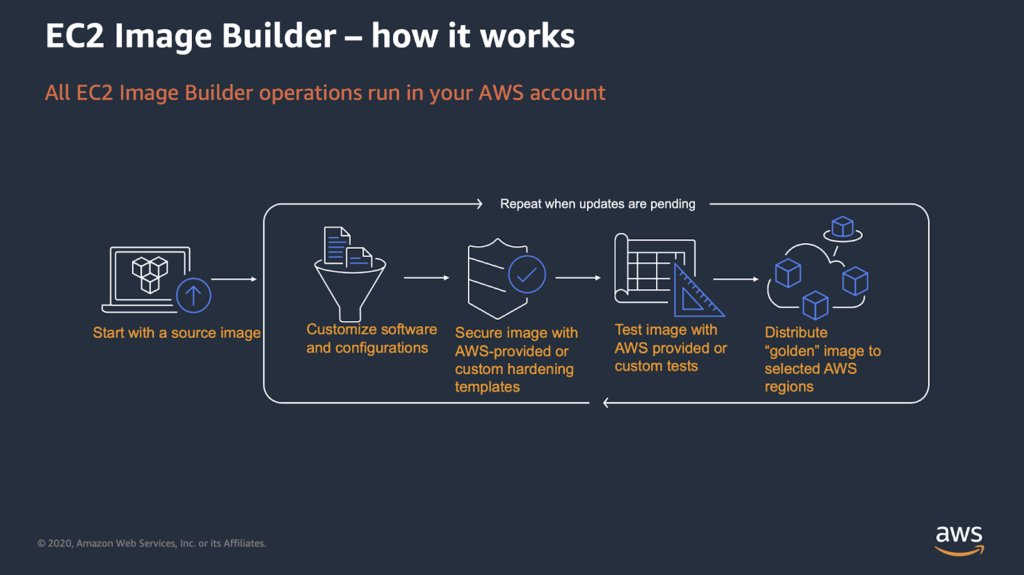
Even if some settings need to be applied after the deployment, this can be done using configuration management tools like Process Chef or Ansible, which allow declaring the configuration manifests and can maintain the configuration in a desired state and prevent configuration drift. This is the key to immutable infrastructure.
A potential operational challenge in provisioning workloads is having the infrastructure spread across more than one infrastructure provider. In situations where on-premises platforms like VMware are used alongside AWS or other cloud providers, the process of providing a consistent provisioning experience becomes more complex. Fortunately, with the help of cross-cloud provisioning tools, the process of creating complex infrastructure building blocks can be simplified to basic item selection in a service catalog.
If you are operating containers with Kubernetes, as long as the solution on-premises or on a cloud provider works using the native Kubernetes API, the container images, in most cases, can also be easily deployed across multiple environments.
Recommended practices
- Even if the number of new workloads does not seem high, start automating the provisioning process to obtain more flexibility in daily operations.
- When switching to or adopting a new infrastructure provider, adopt the existing provisioning and support tools to scale across the new environment. Ensure a consistent workload provisioning experience for the end-user.
- Utilize a central cloud management system such as CloudBolt to prevent configuration drifts and inconsistencies across different environments.
Daily support activities
Any operational department has multiple activities that it needs to perform regularly. These typically include standard break-fix activities, monitoring, taking care of security updates and vulnerability management, and configuring backups.
Those activities classically might have been done manually, but not all of them have to be. The deployment and registration of most operating-system-level agents, such as a monitoring or backup agent, can be completely automated right from workload provisioning. If a configuration change is required, the configuration management tool can roll out the required change on all of the servers where the change is applicable.
Patching and vulnerability management are typically activities that require downtime and, thus, approval from application owners. While agreeing to such maintenance windows is at least as much an organizational topic as a technical one—if not more—plenty of technical implementations are readily available to choose from.
Even if you are currently operating an on-premises data center, it is worth looking at what public cloud providers have to offer in terms of operational tools. For example, Azure Update Manager is a Windows and Linux update management solution that works well for servers in Azure or anywhere else. And it does not cost anything extra.
Especially if public cloud resources are in use, resource tagging should be leveraged. It is useful for both the governance part (assigning owners and cost centers to resources) and can also be used for controlling certain public cloud services, like patching windows or enabling backup policies.
Since security is a key aspect of any infrastructure operations activities, the ability to react to security-related alerts and incidents is also paramount to today’s operations. Besides the appropriate policies and processes, reaction to security incidents should be supported by tooling (typically a SIEM tool) that collects information from all environments and endpoints and can correlate them to help the security operations team quickly understand the ongoing activities.
Recommended practices
- Utilize cloud provider tags not only as part of the governance process but also to control periodic operational activity behavior.
- Look for readily available operational activity solutions from your cloud providers. Those might be applicable even for on-premises workloads.
- Leverage automation using a cloud management platform such as CloudBolt that simplifies your daily workload in a number of ways:
- Integrates seamlessly with monitoring and backup agents, automatically deploying them alongside workloads during provisioning.
- Centralizes control across multiple cloud providers, ensuring consistent tagging and operational activities across your entire hybrid infrastructure.
- Assign owners, cost centers, and even trigger specific actions (like patching or backups) based on tags for precise management in public cloud environments.
Common management layer
Any infrastructure operations team that has gone through vendor changes, organizational transformations, and migrations knows how much effort is involved in new technology adoption. Even more effort is involved when new additional infrastructure providers are involved.
The first step in such cases is to streamline the processes so that they can be applicable across the entirety of the infrastructure. However, streamlining the processes is only part of the solution as the operational activities (or the “how” portion) to achieve the desired outcome might be vastly different between different infrastructures.
In these situations, when there is no oversight over all of the infrastructures that are in place—especially if different teams are taking care of these infrastructures—there is a risk of significant operational practice drift. In the later stages of a migration or transformation project, this drift can introduce unnecessary silos and unwanted operational overhead.
With a platform like CloudBolt, you can transform diverse infrastructures into a unified, manageable entity, eliminating drift, reducing complexity, and empowering your teams to work efficiently and securely across any environment. The platform integrates seamlessly with popular tools like Ansible, Chef, Terraform, and CloudFormation, creating a unified orchestration layer for automated provisioning, configuration management, and resource management.
Recommended practices
- When operating multiple infrastructure providers, ensure that the processes are aligned between them.
- Try to find a set of tooling that works well across these providers. If no common set of tools can be found or if the skill gap is too wide, look for additional tooling platforms that can fill in the gap.
- Consider CloudBolt as a unifying platform for multi-cloud and hybrid infrastructure management.
Learn how CloudBolt’s intelligent optimization platform continuously identifies waste, right-sizes resources, and fine-tunes performance — keeping your hybrid environment efficient over time.
Explore Continuous Cloud Optimization to stay ahead of the curve.
Conclusion
While the public cloud era really does provide benefits in terms of infrastructure management, the increased number of services and capabilities brings their own costs. Organizations can easily utilize multiple infrastructure providers, which means they face even more challenges in terms of governance and the ability to effectively take care of their infrastructure operations.
To handle these challenges, organizations need to not only carefully plan and choose their modernization paths but also rely on modern operational practices and leverage tooling that can fill in the knowledge gaps that they may have.

Related Blogs

Does Your Multi-Cloud Stack Need a Control Plane?
Most infrastructure teams never decide to run a dozen tools across three clouds. It accumulates, one reasonable choice at a…

