
The VMware’s High Availability feature, also known as VMware HA, is a subset of vSphere Availability and part of the broader vSphere suite of technologies. VMware HA provides a way to minimize virtual machine downtime in the event of a hypervisor (ESXi) host failure. With HA, vSphere can detect host failures and can restart virtual machines on other hosts.
This article will review VMware HA concepts, best practices, common misconceptions, and close with a configuration walkthrough.
VMware HA Features and Configuration Options
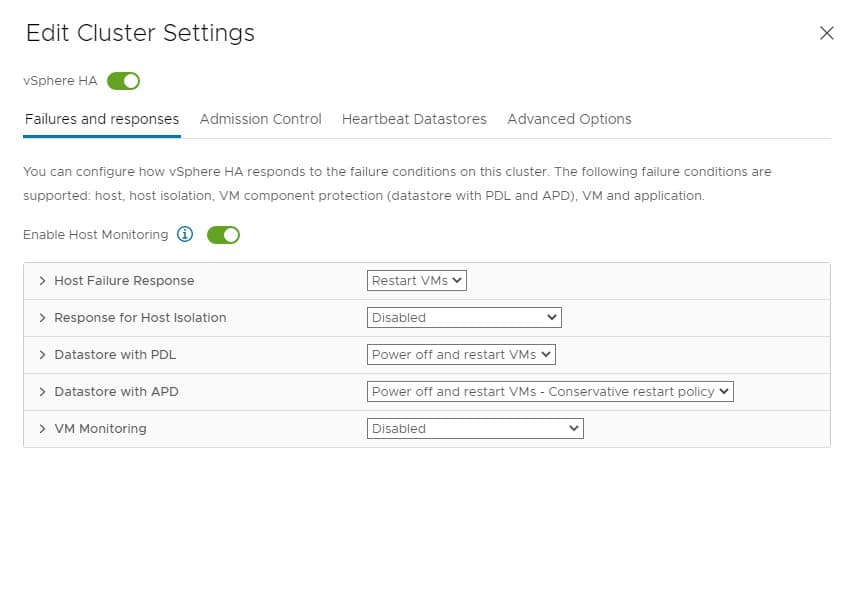
VMware’s High Availability includes multiple configurable features. The right choice of configuration options varies depending on your specific use case (host failure, admission control, etc.). However, the default settings are a great starting point for many vSphere deployments.
The tables below list popular HA features and their configuration options.
| Failure and Response features | |
| Setting | Configuration Options |
|---|---|
| Failure Response | Disabled, Restart VMs |
| VM Restart Policy | Configure on a per VM basis |
| VM dependency restart condition | Resource allocated, Powered on, Guest Heartbeats detected etc. |
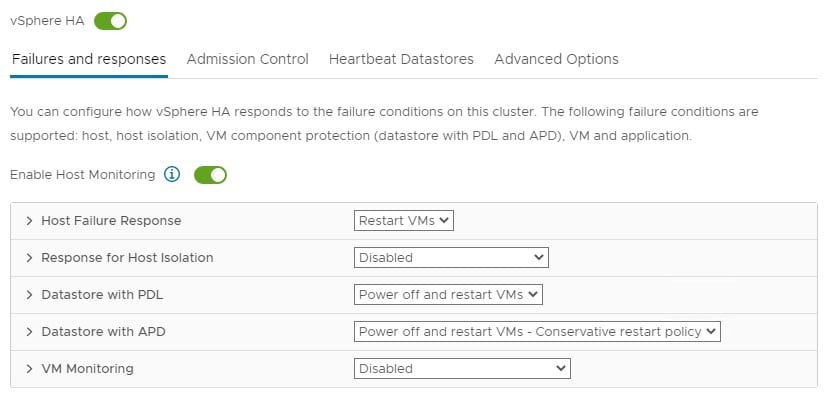
| Response for Host Isolation | Disabled, Power off & restart VMs, Shutdown, and Restart VMs |
| Datastore with PDL (Permanent Device Loss) Response | Disabled, Issue Events, Power off & restart VMs |
| Datastore with APD (All Paths Down) Response | Disabled, Issue Events, Power off & restart VMs |
| VM Monitoring | VM Monitoring, VM & App Monitoring |
| Admission Control features | |
| Setting | Configuration Options |
|---|---|
| Host failures cluster tolerates | Default: 1 |
| Define host failover capacity by | Disabled, Slot Policy, Cluster Resource %, Dedicated failover hosts |
| Percentage | Percentage based |
vSphere High Availability Definitions
In the early days of vSphere, HA’s configurable options were primarily limited to host failures. However, recent versions of HA add support for datastore and virtual machine failures. The expanding feature adds some complexity to VMware HA configuration. Below we’ll guide you through some key HA definitions.
Host Failure Response
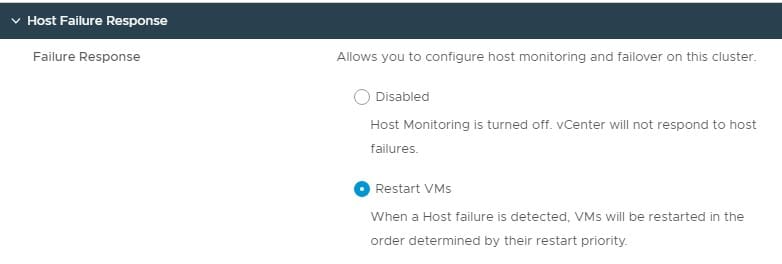
Host failure response is the most well-known HA feature. When a host fails, what do you want vSphere to do? Usually, you want virtual machines on that failed host to be powered back on to other functioning hosts within the same cluster. The “Restart VMs” option does that for you.
Host Isolation
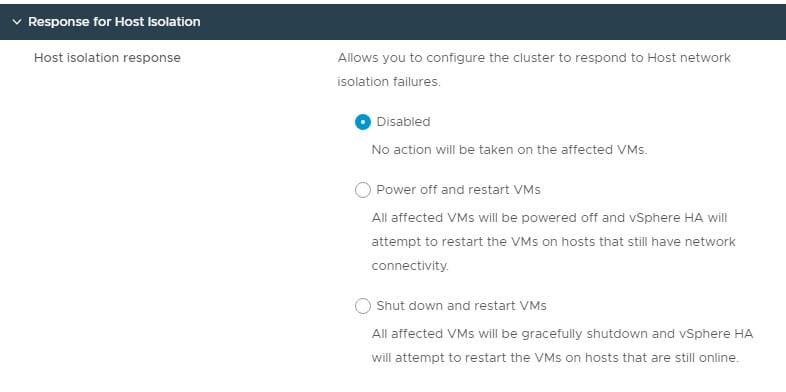
Sometimes a host can become isolated from others in the cluster. When this happens, VMware calls this a host isolation event. If a host becomes isolated, it could be a simple issue with the management network. In that case, virtual machines continue to operate, but vSphere doesn’t know the state of the virtual machines. We must decide if we want virtual machines to be gracefully powered off and back onto other hosts in the cluster or forcefully powered off and back on again.
The main difference here is the graceful power off of the virtual machines. If they hang while powering off, then they might not be brought back online on other hosts. However, forcefully shutting down a virtual machine could corrupt its data. Instead of defining an action, you can keep the default option to do nothing when a host isolation event occurs. In that case, you can manually reboot virtual machines should this become an issue in your environment.
We surveyed 300 IT leaders to find out.
Datastore with PDL
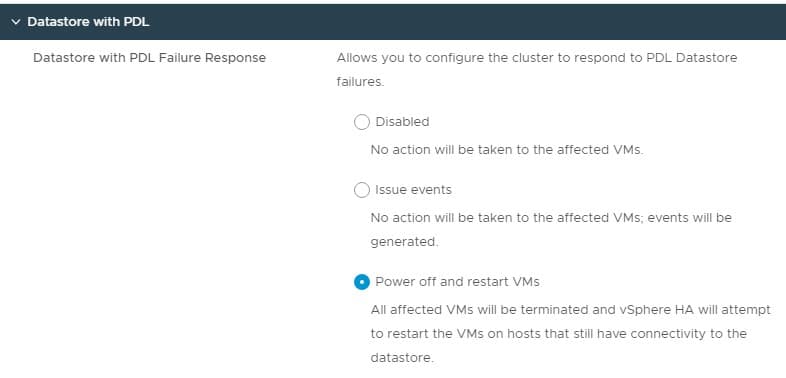
PDL stands for Permanent Device Loss. In the context of datastores, this means that the host can no longer communicate with the datastore and considers it unrecoverable. A PDL state occurs after multiple datastore connection attempts fail.
vSphere HA gives you the option to automatically power off the VMs on the host with the datastore communication issue and power them back onto hosts which can still access the datastore.
Datastore with APD
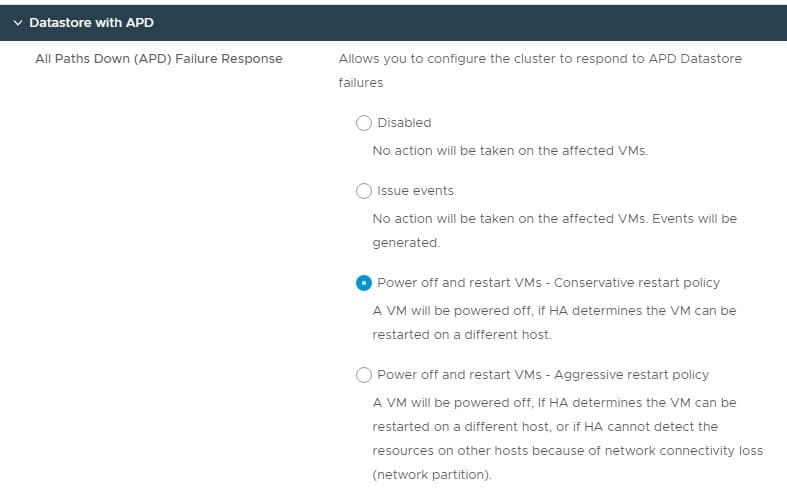
An APD event refers to “All Paths Down”. When an APD event occurs, every path to a given datastore is offline. While paths could come back online, vSphere HA lets us set what to do under this condition. You can do nothing which would result in your virtual machines remaining in a failed state. You can also choose to power off and restart affected virtual machines on other hosts, providing those other hosts still have access to the datastore.
VM Monitoring
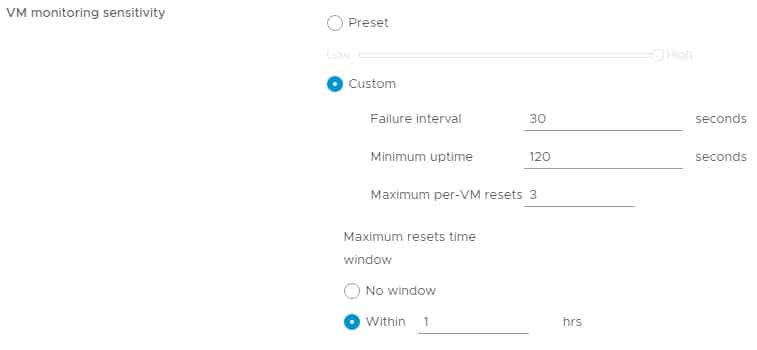
Aside from hosts and datastore failure responses, vSphere HA also has an interesting way to monitor and respond to virtual machine failure.
VMM or VM Monitoring utilizes VMware Tools heartbeats on virtual machines. If vSphere does not receive a heartbeat during the configured time, it determines that the virtual machine has failed and reboots it. VM Monitoring is particularly useful if a virtual machine freezes or encounters a “Blue Screen of Death”.
This feature is disabled by default because you need to weigh the risks of “false positives” against the risk of frozen virtual machines. As always, determine the risk-reward and configure appropriately for the virtual machines in the cluster.
To help prevent false positives, you can use the sensitivity options and the maximum number of resets within a time window option.

Broadcom’s VMware changes are forcing teams to reevaluate what’s next. Get a practical guide to your alternatives and what to consider before making a move.
Recommended VMware HA Prerequisites
Before configuring HA, make sure to address these prerequisites:
- Licensing- First, ensure that all hosts in your target cluster are licenses for HA
- One or more hosts- HA is a cluster-level feature. As a result, HA needs at least two hosts within a cluster to operate.
- Static IP addresses (or reserved DHCP addresses)- Ensure every host uses a static IP for its management interface. If you use DHCP for your hosts, ensure that these addresses have reservations in your DHCP server.
- Management Network- For HA, you need at least one management VMkernel network configured per ESXi host. Every host should be able to communicate with the other hosts in this network. Furthermore, the hosts in this network must be able to communicate with your vCenter Server. The management network can use IPv4 or IPv6.
- Shared Storage & Networks- For HA to reboot virtual machines onto other hosts within the same cluster, all hosts in the cluster must have access to the same shared storage, and all networks must have the same name across the cluster.
- VMware Tools- To leverage Virtual Machine Monitoring, virtual machines in the cluster must have VMware Tools installed.
How does VMware HA work?
All hosts in an HA-enabled cluster report their status to each other during an election process. This process allocates one of the hosts as a “primary”. This process occurs during initial HA configuration or when the last elected primary host fails.
The primary host is responsible for updating your vCenter server with its status and the status of other hosts within the cluster.
Should one of the non-primary hosts fail, the cluster can react and reboot VMs on other hosts. If the primary host fails, the cluster elects a new one, and the failover process commences.
The number one misconception about VMware HA
The most common misunderstanding about vSphere HA is that it uses vMotion to move virtual machines from one host to another. This assumption is incorrect. When a host fails, the VM is already in a powered-off (crashed) state. HA simply powers the virtual machines back on using another healthy host within the cluster. vSphere HA and vMotion are different technologies with different requirements and benefits.
In summary, HA doesn’t require a vMotion network to function. However, it does need shared storage so that other hosts can access the virtual machine files and power the VM back on after a host failure.
VMware HA Best Practices
Provided that you abide by the vSphere HA prerequisites, you should be ready to use HA, but what are the best practices? Let’s take a look.
Number of VMs per host
Be sure to leverage distributed resource scheduler (DRS) features within your clusters. By using DRS, you will ensure workloads are balanced over all hosts in your cluster.
Imagine a scenario where a host running most of your VMs fails. It would take a while for all virtual machines to be powered back on to other healthy hosts. By using DRS, you can minimize downtime due to a host failure.
Large hosts vs. small hosts
As with the previous point, do you want hundreds of virtual machines to be affected due to a host failure or a few dozen? Ensuring that your hosts are not too large and yet not too small is a balancing act. Cluster resilience and hardware costs are both key points to consider when setting up your clusters.
Admission Control
When setting up HA, using Admission Control is generally a good idea. Enabling Admission Control will prevent you from powering on new virtual machines that violate your “Number of host failures to tolerate” setting.
Why does this matter? Consider a scenario when you encounter a host failure. You will want all your virtual machines to have somewhere with enough compute power to run. If you build too many virtual machines and all your hosts are maxed out of CPU or memory, then you will have nowhere for virtual machines to run should a host fail.
Admission Control keeps you from getting into this scenario by informing you that there is not enough capacity to power on new virtual machines.
Concerned about what Broadcom’s VMware acquisition means for your hybrid cloud? Watch experts break down real customer concerns and migration paths.
How to setup VMware HA
As with many vSphere features, the most time-consuming part is learning the technology and the prerequisites. Once you have the knowledge required, the process to set up HA is simply:
- Select your cluster
- Edit configuration
- Toggle the option for vSphere High Availability to on
You can see the simplicity of enabling vSphere HA in the screenshot below:

Once you have enabled vSphere HA, the HA agent will begin installing on all the hosts, and the HA election process will start behind the scenes:


You can then tweak your HA configuration as needed at any time. You can also disable and re-enable HA if required.
CloudBolt’s Cloud Management Platform gives you centralized governance, provisioning, and cost control across VMware and every major cloud provider — so you’re never locked in again.
Explore the Cloud Management Platform to future-proof your infrastructure.
Conclusion
VMware’s vSphere HA solution is an excellent tool for any vSphere admin to protect against various host failure scenarios. While HA is not as robust as Fault Tolerance (another vSphere Availability feature, enabling zero downtime on host failure), it is generally fast enough to respond to host failures and fits most organization’s uptime requirements.
It’s important to remember that HA does not use vMotion to move virtual machines from a failed host to a functioning one. HA simply reboots failed virtual machines on healthy hosts.
Be sure to explore the more advanced features of HA such as datastore APD, PDL, and virtual machine monitoring for the best use of your VMware licensing investment.

Related Blogs

What actually happens when a workload OOMs in production
The pager goes off at 2:47 AM. CrashLoopBackOff on a payment service. The on-call rolls over, opens a laptop, runs…
